
Data modeling is an important step in creating effective Power BI reports. A well-designed data model ensures that the data is clean, relationships are correctly defined, and reports and dashboards are both accurate and efficient.
Data Modeling
To set meaningful goals and track progress effectively, organizations need high-quality data. A clear and well-organized data structure, with consistent and accurate information, forms the foundation for measuring progress and moving forward confidently. That is where data modeling plays an important role in setting up a structured framework of data. A data model helps in understanding:
- Inter-relationships among various data items to users
- Ensures that actionable insights are generated from downstream analytics
- Allows awareness of the best practices concerning the management of data within the organization
- Identification of the most suitable tools to access and handle different kinds of data
- Effective data modeling sets the foundation to lead to information decision-making and continuous improvement
What is Data Modeling in Power BI?
In Power BI, data modeling is the process of shaping, organizing, and structuring of data to make it easier to analyze and visualize. Data modeling involves:
- Understand how data will be combined and organized to make analysis and visualization easier.
- Designing how different data sources will connect and interact.
- Defining relationships between different datasets and data tables.
- Setting up calculations and transformations, calculated columns or measures using DAX (Data Analysis Expressions) to turn raw data into meaningful insights.

A data model is a visual representation of a data system, using diagrams to indicate data objects and their relationship in order to design a database or re-engineer an application.
Core Concepts of Data Modeling in Power BI
Understanding the core concepts of data modeling in Power BI is essential for effective analysis of datasets. Data modeling concepts in Power BI are as follows:
Tables – Tables organize information into records and the attributes of those records into rows and columns, respectively. Each column of table has a datatype and every datatype is very important for data analysis. Tables can be categorized into two category
- Fact Tables – These tables contain quantitative data, such as sales, transactions, or revenue, usually with a large number of records.
- Dimension Tables – These tables contain descriptive data, like customer names, dates, or product categories, which provide context for the facts.
Relationships – Table data can be related with other tables and relationships define how tables connect to each other. In Power BI, if required we can also create relationships between tables to allow the analysis of data across various data sets. Tables can be related and accessed based on:
- Primary and Foreign Keys – A primary key is a unique identifier for a table, and a foreign key is a column in one table that links to the primary key in another table.
- Cardinality – This refers to the type of relationship between tables e.g. one-to-one, one-to-many, many-to-one, many-to-many.
- Cross-Filter Direction – Cross-filter direction determines how filters are applied between related tables e.g. single-direction or bi-directional.
Data Type – There is an assigned data type associated with each column in a table, such as Text or string, Number, Boolean or Date. This represents the type of data supported by that column.
Measures and Calculated Columns
- Measures are applied formulas used within reports and visualizations. These measure values are calculated dynamically with change in options and filters applied. Examples of measures are aggregated calculations like sums, averages.
- Calculated columns are evaluated at the time of enrichment and persisted in the table. They are calculated at row level from existing data using DAX formulas.
Hierarchies – These are the logical structures for drilling down through data hierarchically. For example, Country/State/City is a common geographic hierarchy. Another use for hierarchies is to allow levels of organization within the data, such as Year/Quarter/Month, which can lighten the navigation in reports and visualizations.
Normalization and Denormalization
- Normalization of data is to reduce redundancy and dependency, often splitting tables into smaller, related tables.
- Denormalization is combining related tables to simplify the model and improve performance, often used in reporting.
DAX (Data Analysis Expressions) – DAX is a formula language used to create calculated columns, measures, and custom calculations in Power BI. It includes functions for mathematical operations, logic, text manipulation, and time intelligence.
Types of Data Models in Power BI
In Power BI, there are several types of data models that can be used to structure data for analysis and reporting. Each type serves different purpose and different analysis requirements. Types of data models that can be used in Power BI:
Flat Table
- Structure – Flat tables are single, denormalized tables. Single table contains all the data without separate dimension tables.
- Usage – Flat tables are simple to create and use. These tables are bulky and in-efficient for large datasets or complex queries.
- Example – A single table that includes all sales data, customer information, and product details.
Normalized Model
- Structure – In normalized model data tables are highly normalized. It means tables are split into multiple related tables. This structure reduce redundancy.
- Usage – Normalized model is very common in relational databases like SQL, PostgreSQL, SQL Server etc. Multiple table queries become very complex with this model, that is why it is not much used in Power BI.
- Example – A database where customer data, sales data, and product data are all stored in separate, detailed tables.
Composite or Hybrid Model
- Structure – Composite model combines data from different sources. This allows querying data in both direct query and import modes.
- Usage – Composite model is very useful when we need to combine real-time data with historical data stored in Power BI.
- Example – A model that uses imported data for historical analysis and a direct query to a live database for current data.
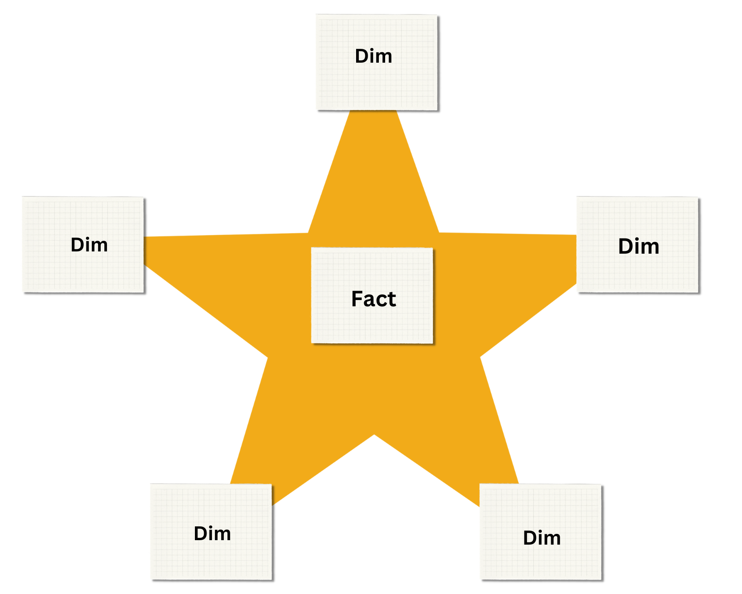
Star Schema
- Structure – Star schema consists of one central fact table connected with number of dimension tables (like a star shape). Ideally, it is good practice to have only one fact table in a data model, but in Power BI we can include multiple fact tables as well. Star schema is simple, maintainable and perform-ant approach.
- Usage – Star schema is mostly used in data warehousing. This model simplifies querying and improves performance.
- Example – A sales fact table connected to dimension tables for products, customers, and time.
Snowflake Schema
Structure – Snowflake schema is similar to the star schema, but with normalized dimensions. It has characteristics from Normalized Model and Start Model.
In Snowflake model dimension tables are further split into additional related tables (like a snowflake). It eliminates redundancy of data but may lead to more complex queries.
Usage – Snowflake schema is mostly used when dimension tables are large and need to be broken down further for efficiency. It can have slower performance compared to start schema. For performance with large data, make a balance between normalization of tables and star schema.
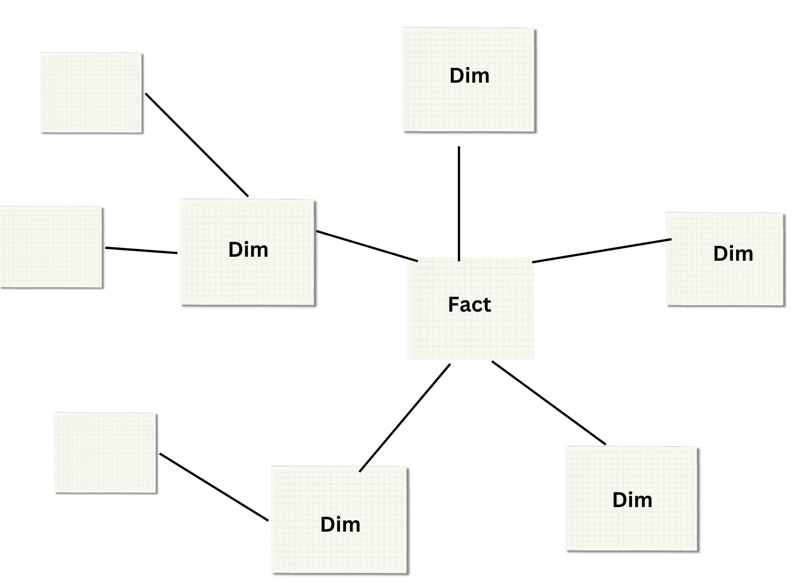
Example Snowflake Schema – A product dimension table that is split into separate tables for product categories and subcategories.
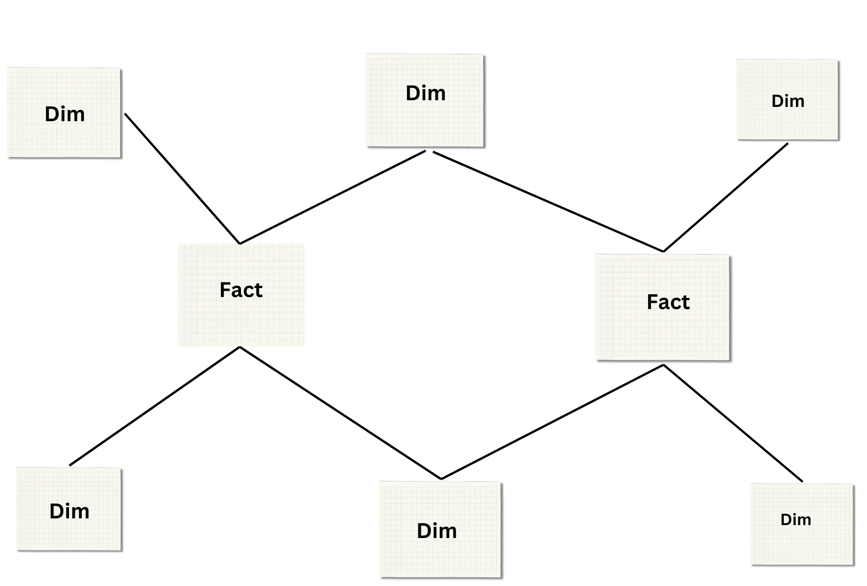
Galaxy (or Galactic) Schema
Structure – Galaxy (or Galactic) schema is a combination of star schema and snowflake schema. Galaxy schema has multiple fact tables shared with dimension tables.
Usage – Galaxy schema is used in complex data environments or scenarios where multiple business processes should be modeled and analyzed together.
Example – A schema with separate fact tables for sales, inventory, and shipments, all sharing the same product and time dimensions.
Star schema vs. Snowflake schema
Star Schema and Snowflake Schema are two most common architectures or designs in the field of Data Warehousing and Business Intelligence. These two schema’s organize data to facilitate perform-ant querying and reporting. Each one of them have its own advantages and disadvantages. The choice between the two depends on the need of some organization. A comparison between these two is as follows:
Star schema
Star schema organizes data elements in one central fact table connected with number of dimension tables. It takes a shape of star. Ideally, it is good practice to have only one fact table in a data model, but in Power BI we can include multiple fact tables as well.
Fact table – Fact table has column linked with foreign keys referencing dimension tables. It is mostly used with facts in measures like the amount of sales and quantity sold.
Dimension Tables – These are denormalized tables that store attributes about the facts. Examples include product details, time, customer information.
Structure – Its structure is much simpler and easier for the user to understand and access data from. Query are less complex and performance is faster.
Advantage
- Easily understandable and accessible for end-users in getting data.
- Faster query performance since there are fewer joins.
- Good for ad-hoc queries and reporting.
Disadvantage
- Data redundancy due to the denormalization procedure.
- This might increase the cost for storage.
- Perhaps more maintenance will be needed in case of changes in the attributes of the dimension tables.
Snowflake schema
The snowflake schema is an advanced and more elaborate database schema. Snowflake schema is similar to the star schema, but with normalized dimension tables. It has characteristics from Normalized Model and Start Model. It takes the shape of a snowflake.
Fact table – This is very similar to fact table in star schema, it composes measures and keys related to dimension tables.
Dimension Tables – These are normalized into a lot of related tables. Data is organized in a hierarchy of levels to reduce data redundancy.
Structure – It has more complex design in comparison with a star schema design. Dimension tables can have multiple related tables. Queries are little complex. Balance normalized approach is required for large dataset.
Advantage
- Reduces data redundancy due to normalization, which requires less storage.
- Easier maintenance during changes in dimensions because the changes are reflected at fewer places
Disadvantage
- Increased complexity, which may be much more difficult for an end-user to understand.
- Slower query performance because it involves multiple joins between normalized tables.
Optimization of Data Model
Optimization of data model is important for Power BI reports to run efficiently.
- Remove Unnecessary Columns and Rows – We should remove unnecessary columns and rows from the dataset. This reduces the data size and leave only relevant data required for analysis.
- Use Appropriate Data Types – Using the correct data types improve performance and reduce storage requirements.
- Reduce Cardinality – High cardinality (unique values in a column) can slow down model performance. We should reduce cardinality by categorizing or grouping data.
- Enable/Disable Relationships – Use the relationship direction wisely. One-way filtering is usually more efficient than bi-directional.
- Aggregation and Summarization – Reduce the data set loaded into Power BI. Try to aggregate data at the source to reduce the amount of data Power BI needs to process.
Best Practices for Data Modeling
- Star Schema Design – Start schema is best approach for most of the scenarios. Organize tables in a star schema with a central fact table connected to dimension tables. This reduces complexity and improves performance.
- Naming Conventions – Use clear and consistent naming for tables, columns, and measures. This increases readability and understanding of data, model and queries to run on model.
- Document Model – Keep notes on relationships, calculations, and logic used in model for future reference. This helps to better understand the model, track the changes in model and performance comparison with different change in models.
- Version Control – Keep backups of different versions of Power BI files with the refinement of data model.
- Data Security – Use Row-Level Security (RLS) in Power BI to restrict data access at the user level.
Summary
In this article, we learned about Data Modeling with Power BI. We also learned about different data models. Following topics were discussed: