
The Transformer is a more advanced architecture for neural networks. This was first introduced in 2017 article by Google, entitled “Attention is All You Need“. Transformer architecture was designed to meet the demands of sequential data and excels on Natural Language Processing or NLP related tasks like machine translation, language modeling, and text generation. Transformer architecture is at the heart of advanced large language models like ChatGPT, BERT, LaMDA, which sparks an excitement and interest in the AI community.
What are Transformers?
Initially, the idea of a transformer was to solve the problem of “sequential data processing“, often referred to as neural machine translation. Generally speaking, this is the task whose purpose is to transform input sequences into output sequences. Hence the name “Transformers”.

What Are Transformer Models?
The Transformer model is a deep neural network model that learns the representation of an input sequence, such as text, to generate new data from that sequence. In other words, a transformer is a form of artificial intelligence that teaches itself to understand and respond in human-like text by breaking down and analyzing patterns in large chunks of text data.
Transformer models has evolved from RNN models like LSTM to Transformers to solve NLP problems. Recurrent Neural Networks, or RNNs, were variants of artificial neural networks. RNNs were designed for processing sequential data.
Transformers works with the self-attention mechanism which enables them to process all input tokens simultaneously. Transformers does not depend on the sequential processing as it was done in RNNs model. This architectural change really made a huge improvement in computational efficiency, by allowing the parallelization of training processes and enables transformers to easily scale when working with big datasets. As a result, transformers models are now one of the base models in deep learning applications today, especially in NLP.
Overview of Transformer Architecture
The Transformer model is built on an encoder-decoder architecture, where
- Encoder takes the input and output as a sequence of context-specific representation. For example the input sentence is “I love learning new languages.”
- Decoder takes the encoder’s output to made the final prediction. Decoder’s translated sentence can be “Ich liebe es, neue Sprachen zu lernen.“
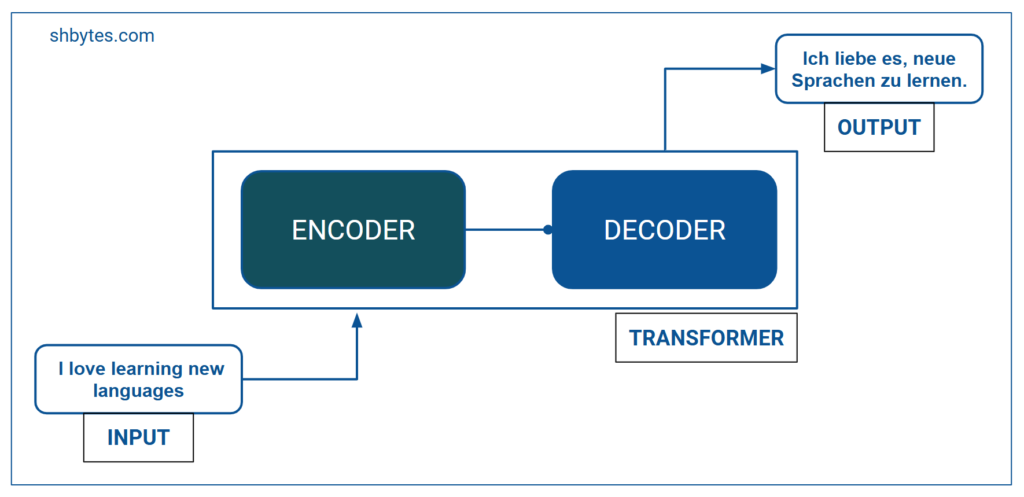
The key components of Transformer architecture are:
- Encoder – It transforms the given input into a sequence of context-specific representations.
- Decoder – It uses the encoder’s output to made predictions one token at a time.
- Attention Mechanism – The attention mechanism draws on the relevant parts of the input sequence by assigning different weights to different tokens.
- Feedforward Neural Network (FFN) – It applies a non-linear transformation to the processed information.
- Positional Encoding – This process adds the information about word order, since Transformers do not have inherent sequential order awareness.
Both encoder and decoder consists of multiple layers in sequence. Number of layers will be same for encoder and decoder. First encoder’s output will be passed as input to second encoder and its output will be passed to the next encoder and so on. Similar pattern followed for decoders as well. Decoder takes input from last encoder and the previous decoder. There were 6 encoders and 6 decoders in the original transformer architecture. But, there is no defined limit for number of encoder and decoders in a transformer, and we can use as many layers as we need.
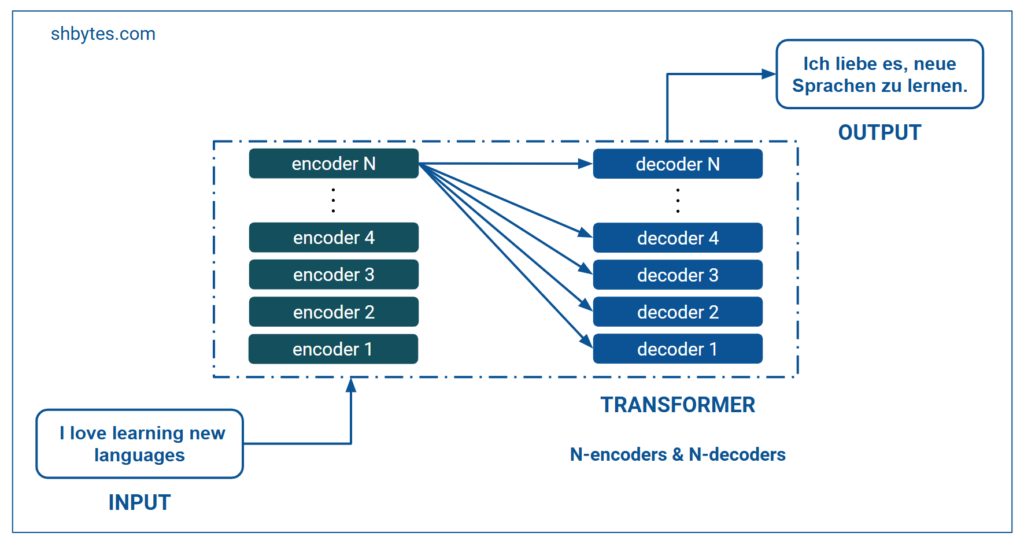
Working of Encoder
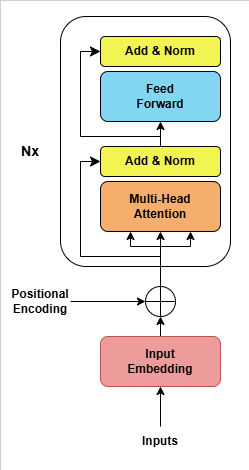
The encoder in the transformer model consists of multiple identical layers. There were six layers in the original transformer architecture. Each layer in the encoder has two major components:
- Multi-Head Self-Attention Mechanism
- Feed-forward Neural Network (FFN)
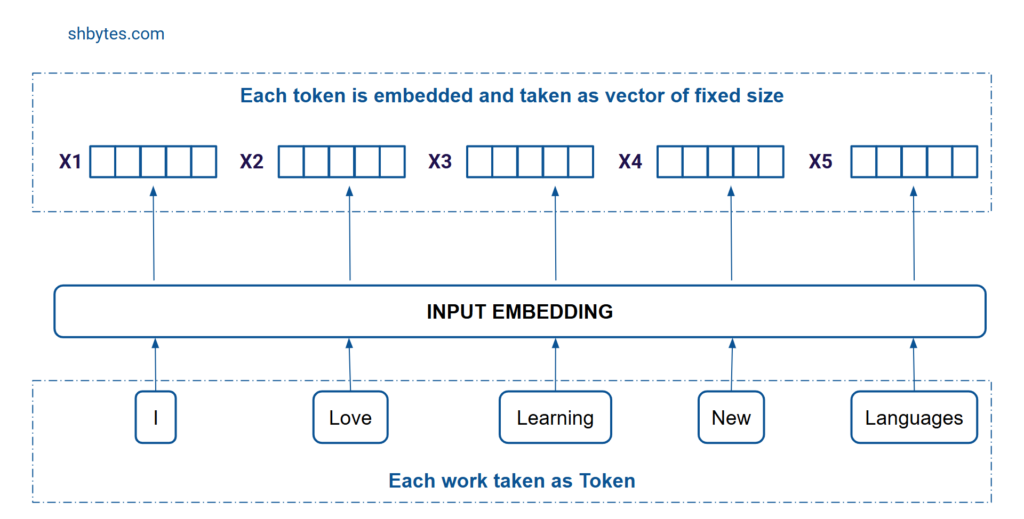
Input Embedding
Input embedding is the first input passed through the encoder layer. Input embedding is part of the first encoder only, subsequent encoders don’t have this layer. Each word or sub-words of the given input text are termed as tokens. Embedding layer converts the input tokens into numerical vectors. Input embedding is useful to understand the contextual meaning of the tokens and to convert them into numerical vectors, each of fixed size 512. These vectors are then passed to the subsequent encoders.
Positional Encoding
In Transformers model, we don’t have any recurring mechanism like RNNs. Transformers uses positional encoding to get positional information about each token in the sequence. Positional encoding is added on top of input embedding. Positional encoding helps to understand the position of each word in the given sentence.
Multi-Head Self-Attention Mechanism
The self-attention mechanism allows each position in the input sequence to give attention to other positions, which helps the model in contextual understanding. Here’s how self-attention mechanism works:
- Self-Attention Calculation – For every input token, there are three vectors that the self-attention mechanism creates:
- Query (Q) – This will be the token that is querying the sequence.
- Key (K) – This would represent the “keys” to every token in the sequence.
- Value (V) – This stores the values or information of each token.
The attention score between tokens is calculated by taking the dot product of the query and key vectors. The result is then divided by the square root of the dimension dk for numerical stability, followed by a softmax function to normalize the scores:
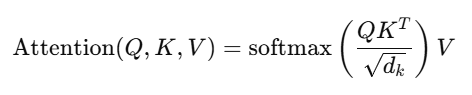
- Multi-Head Attention – Instead of having a single attention function, the model projects queries, keys, and values into different sub-spaces via multiple heads. This allows the model to learn various aspects of the relationship in the sequence. The outputs from each head are then concatenated and linearly transformed.
Feed-forward Neural Network (FFN)
Each encoder layer is followed by a fully connected feed-forward neural network (FFN), which is applied independently to each token. The fully-connected feed-forward network consists of two linear transformations with a ReLU (Rectified Linear Unit) activation in between:
FFN(x) = max(0, xW1 + b1)W2 + b2
This part added non-linearity to the overall transformer architecture and helps the model to learn complex patterns.
Layer Normalization and Residual Connections
Each of these sub-layers (self-attention and FFN) is followed by a layer normalization and residual connections step, which helps the gradients to flow through the model at the time of training and resolves vanishing gradient problems. This can be represented as:
LayerNorm(x + Sublayer(x))
Output of the Encoder
Encoder gives the final output as a set of vectors, where each vector represents the input sequence with much better understanding on the context. In the transformer model, this set of vector will be sent as an input to the decoder. This gives a better contextual understanding to the decoder layer.
Consider it to be like constructing a multi-layer tower, where one can stack up N encoder layers in a stack. Each layer in this stack gets to explore and learn different facets of attention, much like layers of knowledge. This will not only give variety to the insights gained but could strongly enhance the predictive capabilities of the transformer network.
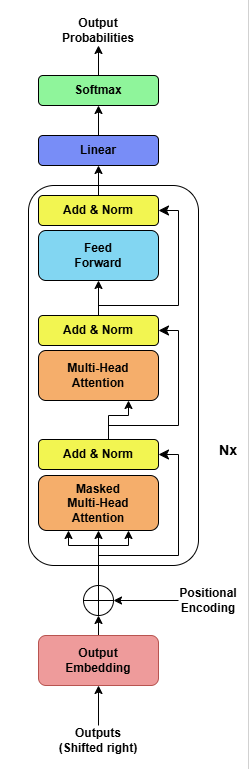
Working of Decoder
Output Embedding
Similar to input embedding for encoder, output embedding added to the decoders. Output embedding is the first inputs passed through the decoder layer. Output embedding is part of the first decoder only, subsequent decoders don’t have this layer.
Positional Encoding
Unlike RNNs, transformers do not have any information on the order of tokens. Positional Encoding provides information on the position of each token in the sequence. The model can thus include the order of words. It’s defined as:
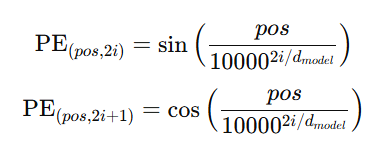
where:
posis the position of the word in the sequence,iis the dimension index.
Positional encoding are added to the input embedding at the start of the model to give it information about the relative positions of tokens.
Multiple layers of Decoder
The decoder is also composed of multiple identical layers, each of which is mainly made up of three components:
- Masked Multi-Head Self-Attention Mechanism
- Encoder-Decoder Multi-Head Attention or Cross Attention
- Feed-forward Neural Network (FFN)
Masked Multi-Head Self-Attention
Self-attentions are masked to avoid attending to subsequent positions in the decoder. This is done to ensure that the predictions made for each position will only depends on previously generated outputs and to keep the auto-regressive nature of language modeling.
For instance, for the given sentence – “I love programming language”. when computing the attention scores for the word “love,” it’s important that “love” doesn’t have access to “programming” or “language,” that are the two next words in the sequence. This ensures that each word only considers the words before it, maintaining the integrity of the sequence during the attention calculation.
Encoder-Decoder Multi-Head Attention or Cross Attention
The decoder has an additional attention mechanism that attends the output of the encoder. This mechanism allows the decoder to focus on relevant parts of the input sequence during output generation. The encoder-decoder attention also uses the multi-head attention mechanism.
Feed-forward Neural Network (FFN)
Similar to the encoder, a feed-forward neural network is added at the decoder to add non-linearity in the representation of each token.
Working of Transformer Model
Let’s now understand how a Transformer works from end to end. let’s see what are the sequence of operations for a translation task say, translating English to French.
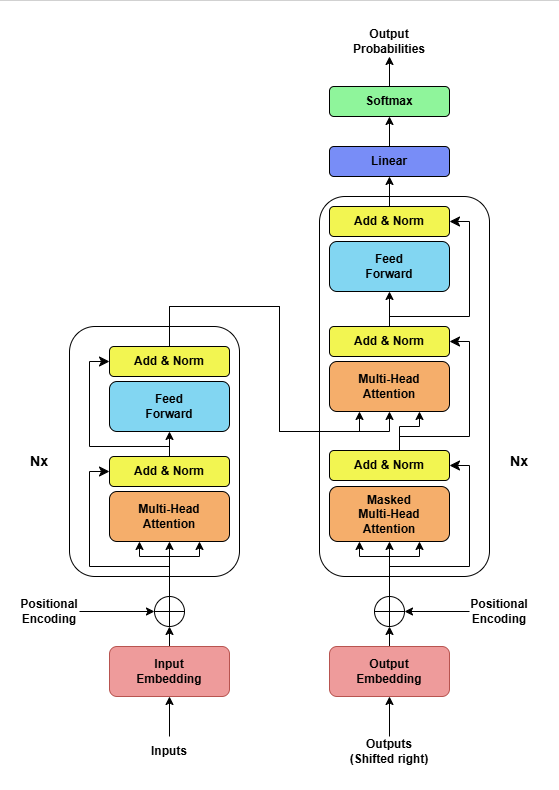
- Encoding the Input Sentence: Each token in the input sentence is embedded into a dense vector and passed to the encoder.
- Applying Self-Attention and FFN: Every encoder layer applies self-attention, that is followed by a feed-forward network, in order to capture the context.
- Passing Encodings to Decoder: The output of the last layer of the encoder is a sequence of encodings, which are passed to the decoder.
- Masked Attention in Decoder: The decoder uses self-attention with masking, so that each token prediction is based only on previously predicted tokens.
- Generating Output: It follows that the decoder attends the output of the encoder and outputs a token in the target language until all sequences of the input are processed.
Advantages of Transformer Models
- Parallel Processing: Transformers do not rely on sequential operations, therefore they are highly parallelizable and faster to train. Since it takes into account all tokens of a sentence at the same time, training for transformers is much quicker than RNNs or LSTMs.
- Handling long-range dependency: Due to self-attention, it allows each token to focus on any other tokens in the sequence. Therefore, transformers handle long-range dependencies more easily.
- Scalability: Transformers can be scaled up by adding more layers and multiple attention heads, it becomes quite versatile when considering big datasets and complicated tasks.
Applications of Transformer Models
Over time, transformers formed the backbone for several large NLP and deep learning models. Some of the applications of transformer models are:
- Natural Language Processing: Used in language translation e.g., Google Translate, generation of languages, and sentiment analysis.
- Vision Transformer (ViT): These transformer models are adapted for image processing and computer vision tasks.
- Pretrained Language Models: Transformers are the base architecture for BERT, GPT, T5, and other language models.
- Speech and Audio Processing: Transformer models are used in tasks like speech recognition and audio generation.
Python implementation of a Transformer Model
Here is a basic example of using the Transformer model in PyTorch:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.nn import Transformer
# Define the Transformer model
class TransformerModel(nn.Module):
def __init__(self, input_dim, output_dim, num_heads, num_layers, dim_feedforward):
super(TransformerModel, self).__init__()
self.transformer = Transformer(d_model=input_dim, nhead=num_heads, num_encoder_layers=num_layers,
num_decoder_layers=num_layers, dim_feedforward=dim_feedforward)
self.fc_out = nn.Linear(input_dim, output_dim)
def forward(self, src, tgt):
transformer_output = self.transformer(src, tgt)
return self.fc_out(transformer_output)
# Initialize model and optimizer
input_dim = 512
output_dim = 512
num_heads = 16
num_layers = 8
dim_feedforward = 2048
model = TransformerModel(input_dim, output_dim, num_heads, num_layers, dim_feedforward)
optimizer = optim.Adam(model.parameters(), lr=0.0002)
# Dummy input data
src = torch.rand(15, 64, input_dim) # (sequence_length, batch_size, input_dim)
tgt = torch.rand(30, 64, input_dim) # (sequence_length, batch_size, input_dim)
# Forward pass
output = model(src, tgt)
print(output.shape) # Expected shape: (tgt_seq_len, batch_size, output_dim)Conclusion
The Transformer model represents a big step improvement in machine learning. It has enabled fast and effective ways of processing sequential data without the constraint of sequential dependencies in RNNs. Multi-head self-attention mechanisms, feed-forward networks, and positional encodings are what make the Transformer model a cornerstone in NLP and other AI applications. This transformer architecture is flexible and efficient; hence, it stands out as a go-to model for most cutting-edge deep learning tasks.