
What are RNNs (Recurrent Neural Networks)
Recurrent Neural Networks, or RNNs, are variants of artificial neural networks. They have been designed for processing sequential data. Other than the conventional feed-forward neural networks, the connections in RNNs loop backward to themselves, which allows it to create and maintain memory of past inputs. This property makes RNNs well-suited for application & tasks related time series, language modeling, and other sequence-based data.
RNNs are designed to recognize patterns in sequences of data, such as time series or natural language. They can use their internal memory to process sequences of varying lengths and learn from previous information.
Key Features:
- Memory – It is possible for the RNN to memorize information about previous inputs due to its hidden states.
- Sequential Processing – It processes sequences one element at a time while keeping track of information about what state it is in at any given time.
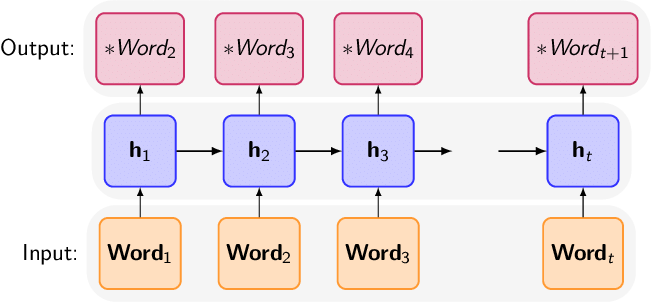
Architecture of RNNs (Recurrent Neural Networks)
The architecture of a basic RNN consists of:
- Input Layer – This is where the input data is sent into the neural network.
- Hidden Layer – This is the core of the RNN (Recurrent Neural Networks) that processes input and maintains the hidden state in memory.
- Output Layer – Produces the output based on the current hidden state.
RNN Cell Structure
The basic operation of an RNN can be described mathematically. At each time step t, the RNN receives an input xt and updates its hidden state ht as follows => ht = f(Wh . ht−1 + Wx . xt + b)
htis the hidden state at timet.ht−1is the hidden state from the previous time step.Whis the weight matrix for the hidden state.Wxis the weight matrix for the input.bis the bias term.fis a non-linear activation function (commonlytanh(Hyperbolic Tangent) orReLU(Rectified Linear Unit)).
The output yt can be calculated as => yt = Wy ⋅ ht + by Where Wy is the weight matrix for the output layer.
Strengths & Limitations of RNNs (Recurrent Neural Networks)
Strengths of RNNs (Recurrent Neural Networks)
- Excel over time – RNNs follows sequence processing, which helps them to learn and predict complex patterns over time.
- Variable Input Length – They can support variable input lengths, so they can comfortably be applied for developing applications such as text or speech processing.
- Internal Memory – RNNs can retain internal memory about the previously given inputs. This helps them learn the dependencies in sequences.
Limitations of RNNs (Recurrent Neural Networks)
- Vanishing Gradient Problem – With the repetitive process, the gradients become very small during the training process, and this creates a problem that the network will struggle to learn long-range dependencies. It is a serious problem when dealing with long sequences.
- Training Difficulty – Compare to feed-forward network model training, RNN models training is very tricky, which requires more time and computational resources.
- Limited Capacity – Internal memory may be limited to capture very long-range dependencies.
Advanced Architectures of RNNs
Several other variants and advanced architectures have evolved to handle and overcome the limitations of the standard RNNs.
Long Short-Term Memory (LSTM)
LSTM (Long Short Term Memory) are RNNs extended to prevent the problem of exploding and vanishing gradients. These LSTM RNNs have a more complex unit structure that includes memory cells and gates which allows the controlled information flow. They can keep the information in memory for extremely long time steps.
Key Components
- Forget Gate – These gates are used to decide whether the previous information should be discarded from the cell states.
- Input Gate – These gates are used to determine what new information shall be stored in the cell state.
- Output Gate – These gates are used to control the information output. These gates decide what information shall be output based on the cell state.
LSTM equations are more complex than the standard RNN, but they allow to maintain long-range dependencies in sequences.
Gated Recurrent Units (GRUs)
GRUs are similar to LSTMs but with a less complex architecture and fewer gates. They are usually faster to train and also good with long-term dependencies
Key Features:
- Update Gate – These gates are used to control how much previous information should be kept in memory.
- Reset Gate -These gates are used to decide how much of the previous information should be removed or forget from the cell states.
Applications of RNNs
There are numerous applications of RNNs, but are especially strong in domains involving sequential data. This includes, among others:
- Natural Language Processing (NLP) – The main tasks involved are language modeling, sentiment analysis, text generation, and machine translation.
- Speech Recognition – The process of taking audio signals and converting those signals into text formats.
- Time Series Prediction – It involves the pattern analysis and prediction of stock prices, weather conditions, and all those things that change with time.
- Video Analysis – Identifying actions or events from a sequence of video frames.
Implementation of RNNs
Here’s a simple implementation of an RNN using Python and TensorFlow/Keras for a sequence prediction task.
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import SimpleRNN, Dense
# Generate dummy sequential data
data = np.random.random((1000, 10, 1)) # 1000 samples, 10 time steps, 1 feature
labels = np.random.random((1000, 1)) # 1000 labels
# Build the RNN model
model = Sequential()
model.add(SimpleRNN(32, input_shape=(10, 1))) # 32 units in the hidden layer
model.add(Dense(1)) # Output layer
model.compile(optimizer='adam', loss='mean_squared_error')
# Train the model
model.fit(data, labels, epochs=10, batch_size=32)Conclusion
Recurrent Neural Networks or RNNs are powerful methods through which one is able to handle sequential data with learning from context and time dependencies. However, with strengths in place, they also have limitations & challenges such as the vanishing gradient problem. There are RNN variants like LSTMs and GRUs, that aim to address such concerns for the development of better performance across many tasks. There are many applications of RNN in NLP, speech recognition and time-series prediction. RNNs will continue playing an integral role in the field of machine learning.
LLM code snippets and programs related to Recurrent Neural Networks (RNNs) – Language Models, can be accessed from GitHub Repository. This GitHub repository all contains programs related to other topics in LLM tutorial.
Related Topics
- What is Tokenization in NLP – Complete Tutorial (with Programs)What is Tokenization Tokenization is one of the major technique in Natural Language Processing (NLP) preprocessing that basically converts raw text into smaller, structured and organized units called tokens. These tokens can be words, subwords, sentences, or even characters. The size of tokens would depend on what form of processing is in view. Why Tokenization Matters in NLP Tokenization is important because Natural Language Processing (NLP) models cannot process texts without breaking it down into some form…
- What are Large Language Models (LLMs)Large Language Models (LLMs) have become the new paradigm for interacting with technology in NLP-based applications. LLMs are taking the center stage in both understanding and generating human language, ranging from conversational chat-bots to graphics generation systems. This article covers what exactly LLMs are, focusing on their main attributes and importance in NLP. What are…
- Natural Language Processing (NLP) – Comprehensive GuideNatural Language Processing (NLP) is a technology in the artificial intelligence domain that involves interaction between human communication and machines understanding. It empowers machines to process human languages in a meaningful and useful way. It enables machines to learn & understand human languages and become capable to generate meaningful output. This makes it possible for…