
Text Preprocessing for LLMs
Preprocessing is an important step to make the raw text ready for the LLM models like ChatGPT and BERT, which take structured input to produce coherent and relevant responses. Proper preprocessing helps in enhancing the model’s performance by enhancing its accuracy and efficiency, also improving generalization by removing noise, standardizing text, and retaining meaningful linguistic patterns. Preprocessing for LLMs involves multiple stages, such as stemming, lemmatization and normalization in text preprocessing.
Preprocessing standardizes the unstructured text into a uniform format that would probably help the model to learn well. This is particularly critical for LLMs, which often see a wide range of inputs with different forms, slang, punctuation styles, and many other variations. Preprocessing of LLMs provide several benefits.
- Standardize Text: Preprocessing tries to standardize the text by eliminating lowercase and uppercase differences, extra spacing, and special characters. This improves the text more consistent.
- Reduced Vocabulary Size: Stemming and Lemmatization are the preprocessing techniques which helps to limit the number of unique words. This reduces the vocabulary size used for training of LLM, which consumes less memory and improves overall performance of the LLM.
- Enhanced Model Performance: Preprocessing removes redundant and extraneous details (e.g., stop-words) and corrects spelling of words given in the text. This makes model’s capacity to focus on meaningful patterns in data and improves overall performance of model.
In this article, we will focus on the techniques involved with Normalization in text preprocessing.
Introduction to Normalization in Text Preprocessing
Normalization is an important concept in text preprocessing for large language models (LLMs) like ChatGPT, BERT. Normalization is a process to make text data cleaner and consistent such that it can be easily used for training of language models. Normalization process tries to improve the quality and accuracy of text data by transforming text into uniform formats. This process follows the steps to eliminate any redundant information & inconsistencies with respect to case-sensitivity (uppercase and lowercase characters), punctuation marks, extra spaces, special characters and even spelling differences.
Normalization process objective is to prepare text data that can be easily and accurately understood by the language models. This process helps improve the accuracy of natural language processing (NLP) tasks. This process is essential for creating clean & reliable input that can lead to more accurate and efficient machine learning models.
There are multiple steps involved in the whole normalization process. Let’s discuss these steps in details.
Normalization Steps in Text Preprocessing for LLMs
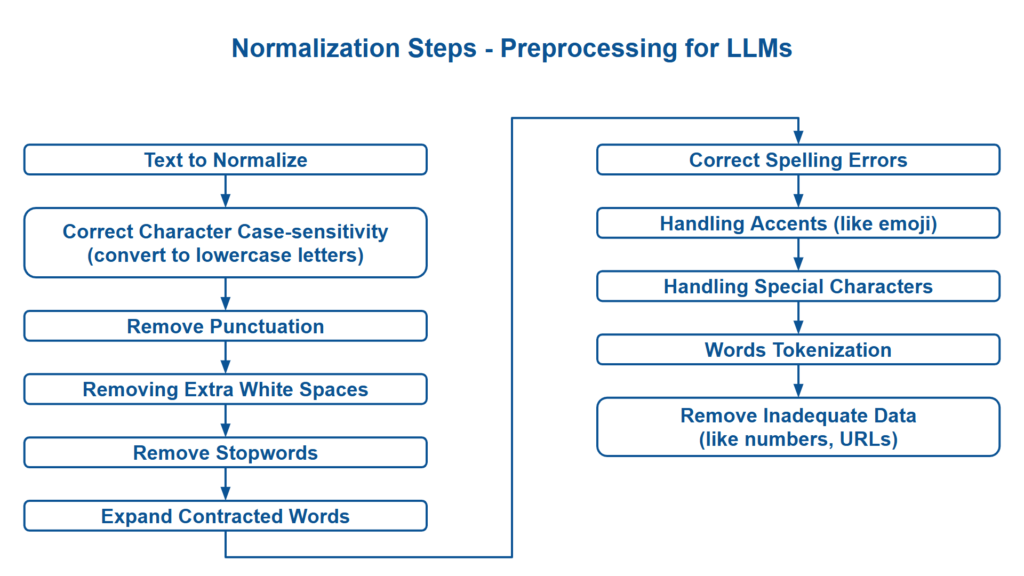
Character Case-sensitivity
This normalization steps focuses on uniform case-sensitivity of characters. It tries to convert all characters into lowercase or uppercase or title-case.
- Lowercase with all lower characters in the word, like “shbytes”.
- Uppercase with all capital characters in the word, like “SHBYTES”.
- Title-case with first character of word in capital and other character in lower case, like “Shbytes”.
def lowercase_text(text):
return text.lower()
def uppercase_text(text):
return text.upper()
def titlecase_text(text):
return text.title()
print(lowercase_text("Shbytes"))
print(uppercase_text("Shbytes"))
print(titlecase_text("shbytes"))
# Output
# shbytes
# SHBYTES
# ShbytesHowever, this step is optional and depends on the context of the language model.
- Case-sensitive models: Some LLMs models are context specific, which uses characters case based on the context e.g., “Apple” as a brand vs. “apple” as a fruit. In such cases, case preservation is preferred and it helps model to provide better results.
- General case-insensitive models: Lowercasing is generally followed with case-insensitive models, which helps to standardize input data and reduce the vocabulary size.
Punctuation Removal
Punctuation removal is another step in the normalization process. Punctuation marks can be removed or retained depending on the model’s requirements. For Instance,
- Retain punctuation: Punctuation carry semantic meaning and is important for text understanding models. Punctuation are kept for language models which requires context understanding.
- Remove punctuation: For simple language tasks like word counting or spelling correction, punctuation marks can be removed.
import re
def remove_punctuation(text):
return re.sub(r'[^\w\s]', '', text)
plain_text = remove_punctuation("Hello, world! This is an example sentence with punctuation: commas, periods, and exclamation marks!")
print(plain_text)
# Output
# Hello world This is an example sentence with punctuation commas periods and exclamation marksWe have Python’s re (Regular Expression) module to remove special characters. re (Regular Expression) module can be used for many other scenarios like to remove URLs, numbers or emails or any other patterns. We can use different regular expression patterns as per the requirement. Following are some regular expression patterns:
[^\w\s]=> Punctuation expressionhttp[s]?://\S+|www.\S+=> URL expression\d+=> Number expression\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+.[A-Z|a-z]{2,}\b=> Email expression
Removing Extra Whitespaces
Extra spaces and newline characters are one of main reason that create inconsistencies in the text. Removing these extra whitespaces ensures uniformity in the text.
def normalize_whitespace(text):
return ' '.join(text.split())
text_with_whitespaces = " This is an example sentence with extra whitespaces "
normalize_text = normalize_whitespace(text_with_whitespaces)
print(normalize_text)
# Output => This is an example sentence with extra whitespacesStopword Removal
Stopwords like “the,” “is,” “in,” and “and,” are common words in a language, which generally carry little meaningful information. In text preprocessing for natural language processing (NLP), we can remove stopwords to focus on words that contains contextual meaning and are more relevant to the text. Removing these stopwords can reduce the vocabulary size and improve model performance.
- Note: For some LLMs, removing stopwords isn’t always recommended, as they may be contextually relevant.
import nltk
nltk.download('stopwords')
stop_words = nltk.corpus.stopwords.words('english')
# stop_words = set(stopwords.words('english'))
def remove_stopwords(text):
return ' '.join([word for word in text.split() if word not in stop_words])
normalize_text = remove_stopwords("This is an example sentence with some stopwords")
print(normalize_text)
# Output => This example sentence stopwordsExpanding Contractions
Some times contracted words like “don’t” or “haven’t” are used in language. Contractions like “don’t” or “it’s” or “haven’t” should be expanded to their full forms (like “do not” or “it is” or “have not”) to reduce ambiguity. This is especially useful in conversational data where contractions are common.
# pip install contractions
import contractions
def expand_contractions(text):
return contractions.fix(text)
expanded_text = expand_contractions("LLMs aren't perfect, but they're helpful in NLP tasks")
print(expanded_text)
# Output => LLMs are not perfect, but they are helpful in NLP tasksSpelling Correction
Spelling correction is important step to improve the quality of the data. This is more important for language models focused on grammar and comprehension. Libraries like textblob and pyspellchecker can be used for automated spelling correction.
# pip install textblob
from textblob import TextBlob
def correct_spelling(text):
return str(TextBlob(text).correct())
corrected_text = correct_spelling("Ths is an exmple of usng library with NLP and LLMs.")
print(corrected_text)
# Output => The is an example of using library with NLP and LLMs.# pip install spellchecker
from spellchecker import SpellChecker
# Initialize the spell checker
spell = SpellChecker()
# Example text with spelling errors
text = "Ths is an exmple of usng library with NLP and LLMs"
# Split the text into words
words = text.split()
# Correct misspelled words
corrected_text = " ".join([spell.correction(word) if word in spell.unknown(words) else word for word in words])
print(corrected_text)
# Output => Ths is an example of using library with NLP and LLMsHandling Special Characters and Accents
Removing or standardizing special characters (like emojis) and accents ensures consistency across datasets with various languages.
# pip install unidecode
import re
from unidecode import unidecode
def remove_accent(text):
# Convert accented characters to ASCII
ascii_text = unidecode(text)
return ascii_text;
def remove_special_characters(text):
# Remove special characters (keeping only letters and spaces)
simple_text = re.sub(r'[^a-zA-Z\s]', '', text)
return simple_text
# Sample text with special characters and accents
sample_text = "Café au lait: A popular drink in cafés across countries like México and España!!"
no_accent_text = remove_accent(sample_text)
# special characters from no_accent_text
normalized_text = remove_special_characters(no_accent_text)
print("Original Text:", sample_text)
print("No Accent Text:", no_accent_text)
print("Normalized Text:", normalized_text)
# Output
# Original Text: Café au lait: A popular drink in cafés across countries like México and España!!
# No Accent Text: Cafe au lait: A popular drink in cafes across countries like Mexico and Espana!!
# Normalized Text: Cafe au lait A popular drink in cafes across countries like Mexico and EspanaThe unidecode function converts accented characters (like “é”, “á”, “í”) to their closest ASCII equivalents, making the text accent-free. This can be useful for search and text processing tasks where accents is not required.
Tokenization
Tokenization is the process of breaking down text into individual units (words or subwords). Tokenization help models learn patterns within the text by creating a standardized input structure.
- Word tokenization: Splits text by words.
- Subword tokenization: Commonly used in LLMs, like BERT and GPT, breaking down rare or compound words (e.g., “running” → “run,” “ning”).
Complete Example Program – Normalization in Text Preprocessing
Combining all these steps, we can create a complete pipeline for text normalization.
import re
import contractions
import nltk
from nltk.tokenize import word_tokenize
from textblob import TextBlob
import unicodedata
# Initialization
nltk.download('stopwords')
stop_words = nltk.corpus.stopwords.words('english')
def normalize_text(text):
# Lowercasing
text = text.lower()
# Remove punctuation
text = re.sub(r'[^\w\s]', '', text)
# Remove extra whitespaces
text = ' '.join(text.split())
# Remove stopwords
text = ' '.join([word for word in text.split() if word not in stop_words])
# Expand contractions
text = contractions.fix(text)
# Remove accents
text = ''.join(c for c in unicodedata.normalize('NFD', text) if unicodedata.category(c) != 'Mn')
# Spelling correction
text = str(TextBlob(text).correct())
# Tokenize
tokens = word_tokenize(text)
# Join tokens back to string
return ' '.join(tokens)
sample_text = "It's imporant to preprocess text for LLMs, isn't it? Removing noise, like stopwords and punctuation, helps models perform better!"
normalized_text = normalize_text(sample_text)
print(normalized_text)
# Output
# important preprocess text alms is not removing noise like stopford punctuation helps models perform betterConclusion
Text normalization preprocessing for LLMs is essential for creating a high-quality dataset for training and evaluation of language models. We can selectively apply each step based on the model’s requirement, keeping context and purpose of the model. This will lead to a more effective and efficient LLM deployment.
In this tutorial, we learned about normalization in text preprocessing and the various steps involved, such as handling character case sensitivity, punctuation removal, removing extra whitespaces, stopword removal, expanding contractions, spelling correction, handling special characters, and tokenization. We have also covered example programs for each step.
LLM code snippets and programs related to Normalization – Preprocessing for LLMs, can be accessed from GitHub Repository. This GitHub repository all contains programs related to other topics in LLM tutorial.
Related Topics
- What is Tokenization in NLP – Complete Tutorial (with Programs)What is Tokenization Tokenization is one of the major technique in Natural Language Processing (NLP) preprocessing that basically converts raw text into smaller, structured and organized units called tokens. These tokens can be words, subwords, sentences, or even characters. The size of tokens would depend on what form of processing is in view. Why Tokenization Matters in NLP Tokenization is important because Natural Language Processing (NLP) models cannot process texts without breaking it down into some form…
- What are N-Gram Models – Language ModelsN-Gram Models N-Gram models are a fundamental type of language model in Natural Language Processing (NLP). These models predict the probability of a sequence of words with regard to the previous word in a fixed window, referred to as “n.” These models have been used in simpler language-related tasks and provide the foundation for more…
- What are Large Language Models (LLMs)Large Language Models (LLMs) have become the new paradigm for interacting with technology in NLP-based applications. LLMs are taking the center stage in both understanding and generating human language, ranging from conversational chat-bots to graphics generation systems. This article covers what exactly LLMs are, focusing on their main attributes and importance in NLP. What are…
- Understanding Static Word Embeddings in NLP – A Complete GuideStatic word embeddings is one of the approach to word representation in natural language processing (NLP). In this word embedding each word is represented as a single, fixed vector, independent of the context in which it was used. These word embeddings are the foundations of modern NLP. Understanding Word Embeddings Word embeddings are a type…
- Understanding Sentence and Document Embeddings in NLPWhat is Sentence and Document Embeddings Sentence and document embeddings are at the core of Natural Language Processing (NLP). These embeddings are represented in a close real-valued vectors format and are created in such a way that these contains the meaning of the whole sentences, paragraphs, or documents. Word embeddings were able to express meaning of single…