
Introduction to Stemming in Text Processing
Stemming is one of the critical text pre-processing technique in Natural Language Processing (NLP) and for Large Language Models (LLMs). Stemming refers to a text processing technique that reduces inflected or derived words to their root or base form, known as the “stem.” To reduce the word to its standard form, stemming algorithm follows the steps to remove word suffixes like “ing,” “es,” “ed”, “er” etc. For example words like “dancer” and “dancing” can be reduced to “dance“.
By reducing inflated words to its root form, stemming helps to group semantically similar words and reduces vocabulary size, thereby improve model efficiency and accuracy with minimal loss of information. This process is especially useful for large datasets in text mining, information retrieval from different sources, and language modeling tasks.
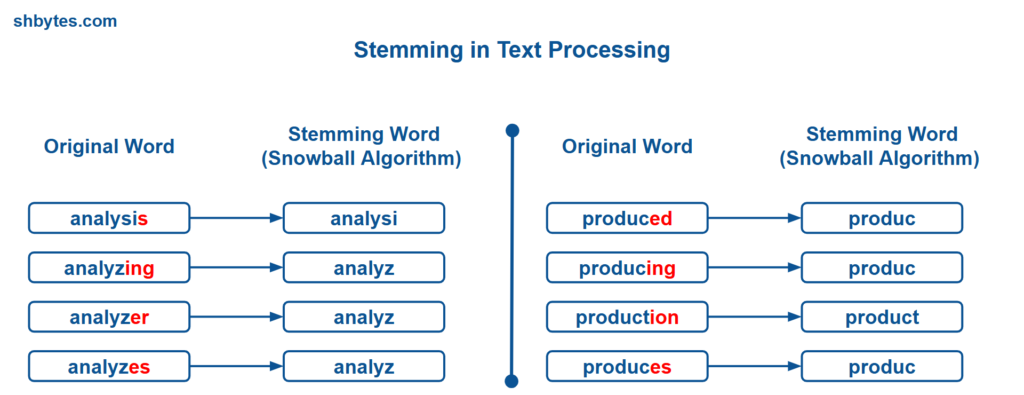
Importance of Stemming in Text Processing and NLP
Stemming provides multiple benefits in pre-processing of text data for LLMs and in NLP.
- Reduced Vocabulary Size – Large Language Models are build to handle millions of tokens. By reducing inflated words to its root form, stemming helps to reduce the number of unique tokens from a language. As a result, it reduces the complexity of data and number of tokens to be handled by a model, which makes easier to train and generalize the model.
- Improved Model Performance – LLMs handling of millions of tokens consume large amount of memory and computation. Some times these multiple token contains multiple minor variations of words like “running” and “runner” are variations of word “run“. Stemming process maps multiple inflated words to its root or stem. This helps language models to easily capture pattern rather than over-fitting to multiple minor variations of words. As a result, it improves model’s performance and efficiency to understand the context faster and give better response.
- Enhanced Semantic Understanding – Stemming helps to generalize the models by removing multiple variations of word. This makes models to better understand the meaning of texts.
- Stemming also helps search engines to find relevant results without need of exact word forms. This improves the flexibility and usability of search engine system.
Types of Stemming Algorithms in NLP
There are multiple stemming algorithms which can be used in text preprocessing for language models. Each stemming algorithm is unique and follows different steps to achieve its objective. These algorithms are used with multiple applications in NLP, but the choice to use a particular algorithm depends multiple factors like the language to which it will be applied, the intended use of the model and the desired trade-off between the quality of stemming and computational efficiency. Stemming algorithms are:
Stemming Algorithm – Porter Stemmer
The Porter Stemmer is one of the most popular stemming algorithm in NLP, which was developed by Martin Porter in 1980. This algorithm works through a series of rule-based transformations applied to the suffixes of words. For example: “Computing” becomes “comput.” and “Connections” becomes “connect.”
The Porter Stemmer’s used multiple-step and heuristic approach, which makes it effective for English language but less adaptable for other languages. Though, Porter Stemmer is an effective algorithm, but sometimes it can produce non-standard roots or stems of the words like “happy” becomes “happi”.
Example Program – Porter Stemmer Stemming Algorithm
Stemming algorithms works on individual words. Before we start stemming, we need to split the sentences into words. This process of splitting sentences into words is known as tokenization.
# pip install nltk
import nltk # import the library
nltk.download('punkt') # download resources - for tokenization
from nltk.tokenize import word_tokenize
text = "Tokenization in a major technique in NLP. Word embeddings help models learn languages"
tokens = word_tokenize(text)
print(tokens)
# Output => ['Tokenization', 'in', 'a', 'major', 'technique', 'in', 'NLP', '.', 'Word', 'embeddings', 'help', 'models', 'learn', 'languages']
from nltk.stem import PorterStemmer # import PorterStemmer for stemming process
porter = PorterStemmer() # create PorterStemmer object
stemmed_words = [porter.stem(word) for word in tokens]
print(stemmed_words)
# Output => ['token', 'in', 'a', 'major', 'techniqu', 'in', 'nlp', '.', 'word', 'embed', 'help', 'model', 'learn', 'languag']From the program output, words like “Tokenization” and “embeddings” are reduced to their roots “token” and “embed” respectively. Sometimes, Porter Stemmer algorithm reduced words which does not seem correct like “languages” reduced to “languag“, but this is a general behavior of this algorithm.
Stemming Algorithm – Snowball Stemmer (Porter2)
The Snowball Stemmer algorithm is an improvement of Porter Stemmer algorithm and is also commonly known as Porter2. Snowball Stemmer algorithm offers more flexibility and the ability to fine-tune the algorithm compared to Porter Stemmer algorithm. It provides capability to be applied to languages other than English. It is more accurate and more stable, particularly in the handling of complex suffixes. Furthermore, it is available in multiple languages.
Example Program – Snowball Stemmer Stemming Algorithm
# pip install nltk
import nltk # import the library
nltk.download('punkt') # download resources - for tokenization
from nltk.tokenize import word_tokenize
text = "Tokenization in a major technique in NLP. Word embeddings help models learn languages"
tokens = word_tokenize(text)
print(tokens)
# Output => ['Tokenization', 'in', 'a', 'major', 'technique', 'in', 'NLP', '.', 'Word', 'embeddings', 'help', 'models', 'learn', 'languages']
from nltk.stem import SnowballStemmer # import SnowballStemmer for stemming process
snowball = SnowballStemmer("english") # create SnowballStemmer object which takes language as an argument
stemmed_words = [snowball.stem(word) for word in tokens]
print(stemmed_words)
# Output => ['token', 'in', 'a', 'major', 'techniqu', 'in', 'nlp', '.', 'word', 'embed', 'help', 'model', 'learn', 'languag']In many cases, Snowball Stemmer algorithm produces similar output as was given by Porter Stemmer algorithm. But with more complex words it can give better results. Also this algorithm is better suited for multilingual applications.
Stemming Algorithm – Lancaster Stemmer
The Lancaster Stemmer algorithm is more aggressive and computationally efficient, hence it usually results shorter stems. For example => “Running” could be reduced to “run.” and “Happiness” could be reduced to “hap.”
Though this algorithm is effective in vocabulary reduction, but sometimes it can be overly aggressive and over-stemming of the words. With over-stemming it results different words to the same stem, and can reduce the semantic meaning of words.
Example Program – Lancaster Stemmer Stemming Algorithm
# pip install nltk
import nltk # import the library
nltk.download('punkt') # download resources - for tokenization
from nltk.tokenize import word_tokenize
text = "Tokenization in a major technique in NLP. Word embeddings help models learn languages"
tokens = word_tokenize(text)
print(tokens)
# Output => ['Tokenization', 'in', 'a', 'major', 'technique', 'in', 'NLP', '.', 'Word', 'embeddings', 'help', 'models', 'learn', 'languages']
from nltk.stem import LancasterStemmer # import LancasterStemmer for stemming process
lancaster = LancasterStemmer() # create LancasterStemmer object which takes language as an argument
stemmed_words = [lancaster.stem(word) for word in tokens]
print(stemmed_words)
# Output => ['tok', 'in', 'a', 'maj', 'techn', 'in', 'nlp', '.', 'word', 'embed', 'help', 'model', 'learn', 'langu']From the output of this program, words like “Tokenization” are stemmed to “tok,” and “embeddings” becomes “embed”. Sometimes this algorithm can lead to over-stemming, which can impact comprehension like for word “major” stemmed to “maj“.
Stemming Algorithm – Lovins Stemmer
The Lovins Stemmer algorithm is among the oldest stemming algorithms in natural language processing (NLP), which was developed by Julie Beth Lovins in 1968. This algorithm focuses on longer words by applying the rules for removing complex suffixes in a single pass. This algorithm is fast, but it is very rarely used in current times. This use relatively simple approach, but in not consistent in giving accurate results. New more refined algorithms like Snowball Stemmer can provide more accurate results compared to Lovins Stemmer algorithm.
Example Program – Lovins Stemmer Stemming Algorithm
class LovinsStemmer:
def __init__(self):
# Define suffixes and corresponding transformations based on the Lovins algorithm
# Note: This is a simplified version with a few examples
self.suffix_rules = {
'ization': 'ize',
'iveness': 'ive',
'lessli': 'less',
'es': 'e',
'els': 'el',
'dings': ''
}
def stem(self, word):
"""Stem the given word using the Lovins algorithm."""
for suffix, replacement in sorted(self.suffix_rules.items(), key=lambda x: -len(x[0])):
if word.endswith(suffix):
return word[: -len(suffix)] + replacement
return word # Return the word unchanged if no suffix is matched
from nltk.tokenize import word_tokenize
text = "Tokenization in a major technique in NLP. Word embeddings help models learn languages"
tokens = word_tokenize(text)
print(tokens)
# Output => ['Tokenization', 'in', 'a', 'major', 'technique', 'in', 'NLP', '.', 'Word', 'embeddings', 'help', 'models', 'learn', 'languages']
# Usage example
stemmer = LovinsStemmer()
stems = [stemmer.stem(word) for word in tokens]
print(stems)
# Output => ['Tokenize', 'in', 'a', 'major', 'technique', 'in', 'NLP', '.', 'Word', 'embed', 'help', 'model', 'learn', 'language']- Suffix Rules: The
suffix_rulesdictionary defines some common suffix transformations. These mappings are simplified and focus on common end-suffix. We can define these rules as per our requirement. In this example, we have used limitedsuffix_rules, but in original algorithm can have more such rules. stemMethod: This method checks each suffix for the key insuffix_rulesdictionary and replaces it with its corresponding value. The longest suffixes are checked first to ensure maximal removal.- Example Usage: We can test this by providing words with common suffixes that the Lovins stemmer targets, e.g.,
Tokenizationconverted toTokenize.
Regex-based Stemming
Regular expressions (regex) can be used to define custom stemming rules based on patterns. This stemming approach is more similar to Lovins Stemmer algorithm. Regex-based stemming is flexible and language-independent but requires in-depth knowledge of linguistic rules.
Example Program – Regex-based Stemming
import re
class RegexStemmer:
def __init__(self):
# Define regular expression patterns for common suffixes
self.suffix_patterns = [
(r'ization$', 'ize'),
(r'iveness$', 'ive'),
(r'es$', 'e'),
(r'els$', 'el'),
(r'dings$', ''),
]
def stem(self, word):
"""Apply regex-based stemming to the given word."""
for pattern, replacement in self.suffix_patterns:
if re.search(pattern, word):
return re.sub(pattern, replacement, word)
return word # Return the word unchanged if no pattern is matched
from nltk.tokenize import word_tokenize
text = "Tokenization in a major technique in NLP. Word embeddings help models learn languages"
tokens = word_tokenize(text)
print(tokens)
# Output => ['Tokenization', 'in', 'a', 'major', 'technique', 'in', 'NLP', '.', 'Word', 'embeddings', 'help', 'models', 'learn', 'languages']
# Usage example
stemmer = RegexStemmer()
stems = [stemmer.stem(word) for word in tokens]
print(stems)
# Output => ['Tokenize', 'in', 'a', 'major', 'technique', 'in', 'NLP', '.', 'Word', 'embed', 'help', 'model', 'learn', 'language']Compare Stemming Algorithms
import nltk # import the library
nltk.download('punkt') # download resources - for tokenization
from nltk.tokenize import word_tokenize
text = "Tokenization in a major technique in NLP. Word embeddings help models learn languages"
tokens = word_tokenize(text)
from nltk.stem import PorterStemmer # import PorterStemmer for stemming process
from nltk.stem import SnowballStemmer # import SnowballStemmer for stemming process
from nltk.stem import LancasterStemmer # import LancasterStemmer for stemming process
# Apply each stemmer
porter_stemmed = [PorterStemmer().stem(word) for word in tokens]
snowball_stemmed = [SnowballStemmer("english").stem(word) for word in tokens]
lancaster_stemmed = [LancasterStemmer().stem(word) for word in tokens]
# Display the results
print("Original Tokens:", tokens)
print("Porter Stemmed:", porter_stemmed)
print("Snowball Stemmed:", snowball_stemmed)
print("Lancaster Stemmed:", lancaster_stemmed)
# Output
# Original Tokens: ['Tokenization', 'in', 'a', 'major', 'technique', 'in', 'NLP', '.', 'Word', 'embeddings', 'help', 'models', 'learn', 'languages']
# Porter Stemmed: ['token', 'in', 'a', 'major', 'techniqu', 'in', 'nlp', '.', 'word', 'embed', 'help', 'model', 'learn', 'languag']
# Snowball Stemmed: ['token', 'in', 'a', 'major', 'techniqu', 'in', 'nlp', '.', 'word', 'embed', 'help', 'model', 'learn', 'languag']
# Lancaster Stemmed: ['tok', 'in', 'a', 'maj', 'techn', 'in', 'nlp', '.', 'word', 'embed', 'help', 'model', 'learn', 'langu']From the output of example program to compare stemming algorithms:
- Porter Stemmer generally produces good results by creating correct and meaningful stems. But this algorithm can sometimes give wrong stem and keeps unusual truncations like for “languages” it stemmed to “language” but could be “lang” .
- Snowball Stemmer is more similar to Porter Stemmer but offers a balanced approach. It produces stems that keeps more meaningful forms.
- Lancaster Stemmer is more aggressive and can sometimes result in over-stemming. This can be seen from the result like “Tokenization” stemmed to “token” and “technique” stemmed to “techn“.
Stemming in Industrial LLM Applications
Use Cases of Stemming in LLM Applications
- Text Classification and Sentiment Analysis – The stemming helps to reduce the vocabulary size by reducing related words into a root form for example “liked,” “likes,” “liking” all stemmed to “like“. This helps the model to generalize better by focusing on core concepts rather than variations in word forms.
- Search Engines and Information Retrieval Systems – Stemming allows search engines to retrieve documents containing related words by reducing them to a common root form. For example, In case of searching for “running“, the search engine would also return results for “run” and “ran.”
- Chatbot Responses and Text Generation – In these applications, the intent of user input is realized through the reduction of the same word to its root form. It simplifies the recognition of users intent and ensures consistency in responses.
- In applications like Named Entity Recognition (NER) and Part-of-Speech (POS) tagging, stemming helps reduce ambiguities by standardizing word forms, this helps in the identification of similar entities in different contexts.
- Content Filtering algorithms can use stemming to detect inappropriate or unwanted content more effectively by identifying root words and variations (e.g., “hate,” “hated,” “hating”).
- In applications like SEO, keyword extraction, or document tagging, stemming helps identify primary keywords and themes the use of root words, and will create more appropriate tagging.
Challenges and Limitations of Stemming
Despite multiple benefits and use-cases of stemming, it has some limitations and faces many challenges.
- Loss of Semantic Nuance: Too much information is removed by over-stemming, which leads to ambiguity between words with distinct meanings.
- Language and Domain Dependency: Porter Stemmer and Lancaster Stemmer algorithms focuses on the English language and do not work efficiently for those languages that have complex mophology.
- Aggressiveness in Stemming: Algorithms like Lancaster Stemmer may produce overly aggressive reductions, which can distort semantic understanding.
Conclusion
Therefore, stemming is still a basic technique in the pre-processing of both NLP and LLM, providing computational efficiency and thereby guaranteeing better model performance. Despite some limitations, stemming allows LLMs to process large textual data with millions of tokens while enhancing generalization and reducing memory costs. We discussed multiple stemming algorithms, by understanding these algorithms and selecting the right stemming approach, developers and data scientists can effectively use stemming to get their LLMs work more efficiently.
LLM code snippets and programs related to Stemming in Text Processing, can be accessed from GitHub Repository. This GitHub repository all contains programs related to other topics in LLM tutorial.
Related Topics
- Simplifying Lemmatization in Text Processing – Complete Tutorial (with Programs)Introduction to Lemmatization in Text Processing Lemmatization in text processing is an important technique in natural language processing (NLP). Similar to stemming, lemmatization works to transform every word into its base or dictionary form known as lemma. For instance, “running” becomes “run,” “better” becomes “good,” and “children” becomes “child.” But lemmatization work differently than stemming.…
- Understanding and Implementing Stemming in Text ProcessingIntroduction to Stemming in Text Processing Stemming is one of the critical text pre-processing technique in Natural Language Processing (NLP) and for Large Language Models (LLMs). Stemming refers to a text processing technique that reduces inflected or derived words to their root or base form, known as the “stem.” To reduce the word to its…
- Normalization in Text Preprocessing for LLMs – Complete Tutorial (with Programs)Text Preprocessing for LLMs Preprocessing is an important step to make the raw text ready for the LLM models like ChatGPT and BERT, which take structured input to produce coherent and relevant responses. Proper preprocessing helps in enhancing the model’s performance by enhancing its accuracy and efficiency, also improving generalization by removing noise, standardizing text,…
- Understanding Sentence and Document Embeddings in NLPWhat is Sentence and Document Embeddings Sentence and document embeddings are at the core of Natural Language Processing (NLP). These embeddings are represented in a close real-valued vectors format and are created in such a way that these contains the meaning of the whole sentences, paragraphs, or documents. Word embeddings were able to express meaning of single…
- Understanding Static Word Embeddings in NLP – A Complete GuideStatic word embeddings is one of the approach to word representation in natural language processing (NLP). In this word embedding each word is represented as a single, fixed vector, independent of the context in which it was used. These word embeddings are the foundations of modern NLP. Understanding Word Embeddings Word embeddings are a type…
This is nicely said! !
Wow quite a lot of useful info.