
Introduction to Lemmatization in Text Processing
Lemmatization in text processing is an important technique in natural language processing (NLP). Similar to stemming, lemmatization works to transform every word into its base or dictionary form known as lemma. For instance, “running” becomes “run,” “better” becomes “good,” and “children” becomes “child.”
But lemmatization work differently than stemming. Unlike the stemming algorithms which are not context-aware, lemmatization is context-aware and give priority to the context in which words are used. It considers the linguistic meaning of words and decides the correct form of a word based on its grammatical usage (e.g., whether it’s a noun or a verb). For example “better” can be transformed into “good“. This makes lemmatization process more accurate and generally preferred for applications where linguistic meaning and grammatical context is important.
In human languages especially in English, words can be represented in multiple forms. This representation of the words requires understanding of the word’s part of speech (POS) and understanding of the context in which a particular word is used. For example:
- Depending on the context of the sentence, verbs like “run” can appear as “running,” “ran,” or “runs“.
- “better” could be used as an adjective or a verb. Lemmatization would return “good” if it’s an adjective or “better” if it’s a verb. This depends on the context and understanding of the word’s part of speech (POS).
- Some other examples of lemmatization are: “studies” => “study”, “leaves” (noun) => “leaf”, “geese” => “goose”
Stemming and Lemmatization in Text Processing
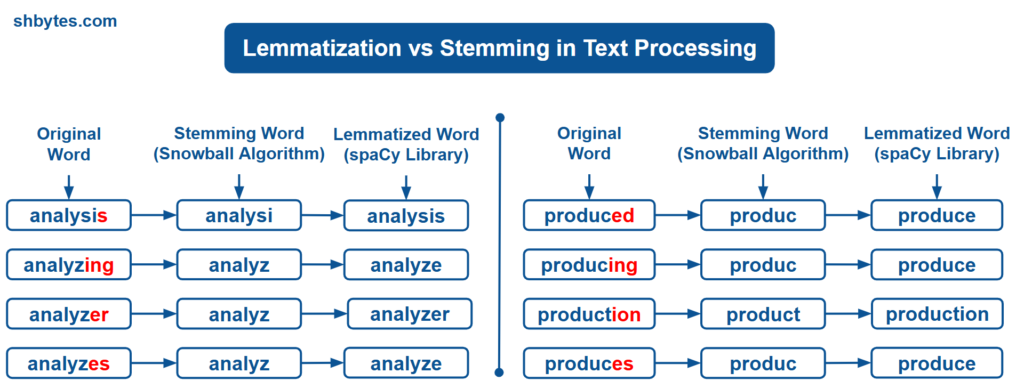
Purpose of both Stemming and Lemmatization techniques is to transform the words to its base form. But, both these techniques works in different approach.
- Stemming follows simple rules-based approach to remove suffixes (like “ing“, “ed“, “es“) from the words. This approach is not context-aware. Stemming algorithms are much faster but can produce non-standard words that may not be actual word. Example – “technique” reduced to “techniqu“; “languages” reduced to “languag“
- Lemmatization is comparatively more complex process, which requires context awareness, morphological analysis and part of speech (POS) tagging. This approach transforms words to its actual dictionary forms. This approach requires more resources to work. This approach is much better and can give accurate results. Examples “teach,” “taught,” “teaching” => “teach“; “diagnose,” “diagnosed,” “diagnoses” => “diagnose“
In general, lemmatization is a better approach and is preferred for applications where contextual understanding and meaning of sentence is important, while stemming is often faster and suitable for search engines or other information retrieval tasks.
Lemmatization Algorithms in Python
To write lemmatization algorithm in Python, we can use two popular Python libraries for NLP: NLTK and spaCy. These Python libraries provide easy-to-use lemmatization functions. Both these Python libraries for NLP are very good but they follows different approach.
Follow following commands to setup these libraries on local environment:
- To install =>
pip install nltk spacy - To download language model for spaCy =>
python -m spacy download en_core_web_sm
Lemmatization with NLTK’s WordNet lemmatizer
NLTK (Natural Language Toolkit) is a popular library for NLP in Python. It provides access to the WordNet lemmatizer, which can be used to perform lemmatization based on the given text.
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import word_tokenize
import nltk
nltk.download('wordnet') # download resources - for tokenization
# Initialize the lemmatizer
lemmatizer = WordNetLemmatizer()
# Sample text
text = ("In NLP, lemmatization refines text by reducing words to their base forms. "
"This help models to understand linguistic structures and contexts more accurately.")
# Tokenize the text
tokens = word_tokenize(text)
# Apply lemmatization
lemmatized_words = [lemmatizer.lemmatize(word) for word in tokens]
print("Original words:", tokens)
print("Lemmatized words:", lemmatized_words)
# Output
# Original words: ['In', 'NLP', ',', 'lemmatization', 'refines', 'text', 'by', 'reducing', 'words', 'to', 'their', 'base', 'forms', '.', 'This', 'help', 'models', 'to', 'understand', 'linguistic', 'structures', 'and', 'contexts', 'more', 'accurately', '.']
# Lemmatized words: ['In', 'NLP', ',', 'lemmatization', 'refines', 'text', 'by', 'reducing', 'word', 'to', 'their', 'base', 'form', '.', 'This', 'help', 'model', 'to', 'understand', 'linguistic', 'structure', 'and', 'context', 'more', 'accurately', '.']From the output of this example program, the WordNet-Lemmatizer has converted “words” to “word” and “forms” to “form.” However, it leaves words like “linguistic” and “understand” unchanged because it doesn’t know their part of speech.
Lemmatization including Part of Speech (POS) Tagging with NLTK
To improve accuracy with lemmatization, we can include part of speech (POS) tags to guide the lemmatizer that a particular word is an “adjective“, “verb“, “noun“, or “adverb“. NLTK provides a simple POS tagger like averaged_perceptron_tagger_eng that assigns each word a POS category. The WordNet lemmatizer performs better with this additional information.
# import libraries required for tokenization
import nltk
from nltk.tokenize import word_tokenize
# Sample text
text = ("In NLP, lemmatization refines text by reducing words to their base forms. "
"This help models to understand linguistic structures and contexts more accurately.")
# Tokenize and lemmatize with POS
tokens = word_tokenize(text)
# import libraries required for Part of Speech (POS) lemmatization
from nltk.corpus import wordnet
from nltk.stem import WordNetLemmatizer
nltk.download('averaged_perceptron_tagger_eng')
# Function to convert POS tags to WordNet format
def get_wordnet_pos(word):
tag = nltk.pos_tag([word])[0][1][0].upper()
tag_dict = {"J": wordnet.ADJ, "N": wordnet.NOUN, "V": wordnet.VERB, "R": wordnet.ADV}
return tag_dict.get(tag, wordnet.NOUN)
# Initialize the lemmatizer
lemmatizer = WordNetLemmatizer()
lemmatized_words = [lemmatizer.lemmatize(word, get_wordnet_pos(word)) for word in tokens]
print("Original words:", tokens)
print("Lemmatized words:", lemmatized_words)
# Output
# Original words: ['In', 'NLP', ',', 'lemmatization', 'refines', 'text', 'by', 'reducing', 'words', 'to', 'their', 'base', 'forms', '.', 'This', 'help', 'models', 'to', 'understand', 'linguistic', 'structures', 'and', 'contexts', 'more', 'accurately', '.']
# Lemmatized words: ['In', 'NLP', ',', 'lemmatization', 'refines', 'text', 'by', 'reduce', 'word', 'to', 'their', 'base', 'form', '.', 'This', 'help', 'model', 'to', 'understand', 'linguistic', 'structure', 'and', 'context', 'more', 'accurately', '.']In this program, function get_wordnet_pos(word) is defined to get the Part of Speech (POS) tag for the word. From the output of this example program, WordNet-Lemmatizer with Part of Speech (POS) Tagging has converted the word “reducing” to “reduce” and achieved greater accuracy, which was not the case with basic WordNet-Lemmatizer.
Lemmatization with spaCy
spaCy is another popular Python library for NLP that provides built-in lemmatization with more advanced language models. It automatically performs lemmatization along with Part of Speech (POS) tagging. This library is very efficient and provides accurate results.
# pip install spacy
import spacy
# before load, download spacy module - python -m spacy download en_core_web_sm
# Load the spaCy language model
nlp = spacy.load("en_core_web_sm")
# Sample text
text = ("In NLP, lemmatization refines text by reducing words to their base forms. "
"This help models to understand linguistic structures and contexts more accurately.")
# Process the text
doc = nlp(text)
# Extract lemmas
lemmatized_words = [token.lemma_ for token in doc]
print("Original words:", doc)
print("Lemmatized words:", lemmatized_words)
# Output
# Original words: In NLP, lemmatization refines text by reducing words to their base forms. This help models to understand linguistic structures and contexts more accurately.
# Lemmatized words: ['in', 'NLP', ',', 'lemmatization', 'refine', 'text', 'by', 'reduce', 'word', 'to', 'their', 'base', 'form', '.', 'this', 'help', 'model', 'to', 'understand', 'linguistic', 'structure', 'and', 'context', 'more', 'accurately', '.']From the output of this example program, spaCy automatically included Part of Speech tagging to perform lemmatization and returns contextually correct lemmas like “reducing” converted to “reduce“.
NLTK vs. spaCy – Which Library to Choose for Lemmatization
- NLTK: This Python library for NLP is good for basic or simple applications where we don’t need high-speed processing. NLTK library provides more control but requires additional steps like extra code to include POS tagging.
- spaCy: This Python library for NLP provide fast processing and is more efficient, especially for large datasets or real-time applications. We don’t to write extra lines of code to perform Part of Speech (POS) tagging and provides accurate results.
Lemmatization Use-Cases and Best Practices
Why Use Lemmatization
Lemmatization has a number of advantages for different types of applications. Because of its processing with context-awareness, it is more useful for applications that require grammatical correctness and awareness of context.
- Vocabulary Size: Like stemming, lemmatization transforms the various word forms into standard forms, hence decreases the number of unique words and total size of vocabulary. Hence, it simplifies the data to be analyzed and used for training of language models.
- Retention of Meaning (Context Awareness): Lemmatization is context-sensitive. It often retains grammatical and semantic meaning linked with the words in the given text. This feature make it quite useful for applications which require linguistic precision, such as text summarization and sentiment analysis.
- Improved Model Performance: Lemmatization reduces words to their roots, enabling models to identify patterns without losing meaning of the words. This helps to improve the performance of models for NLP tasks.
Best Practices for Lemmatization
Lemmatization is an important step in the text preprocessing of NLP. This will clean up the data for more standardized datasets that language models can use. We need to understand some points on how to choose Lemmatization over Stemming:
- Lemmatize when Context matters: When we want grammatical meaning of words to be preserved and need to simplify text more precisely, then we can use Lemmatization.
- Merge with Stopword Removal: Lemmatized text when merged with Stopword removal, it further reduces the noise in text data. It helps to make text more consistent.
- Testing Different Libraries: While working with a large amount of data, or if faster processing is needed, use spaCy. But otherwise, NLTK can work just fine for smaller, more controlled workflows.
Conclusion
Lemmatization is a basic technique in natural language processing that reduces words to their dictionary form, or lemmas, keeping the meaning and grammatical context intact. This process decreases variations of word, for example, “diagnose,” “diagnosed,” “diagnoses” => “diagnose” and makes it possible for lemmatization to help create a more standardized dataset that is very useful for various applications such as text classification, sentiment analysis, and machine translation.
Lemmatization, in this respect, tends to be more accurate than stemming because it can generally understand the context in which words appear. In general, this addition to your pre-processing pipeline with either a library like NLTK or spaCy will go a long way toward improving the quality of your NLP models.
LLM code snippets and programs related to Lemmatization in Text Processing, can be accessed from GitHub Repository. This GitHub repository all contains programs related to other topics in LLM tutorial.
Related Topics
- Natural Language Processing (NLP) – Comprehensive GuideNatural Language Processing (NLP) is a technology in the artificial intelligence domain that involves interaction between human communication and machines understanding. It empowers machines to process human languages in a meaningful and useful way. It enables machines to learn & understand human languages and become capable to generate meaningful output. This makes it possible for…
- Normalization in Text Preprocessing for LLMs – Complete Tutorial (with Programs)Text Preprocessing for LLMs Preprocessing is an important step to make the raw text ready for the LLM models like ChatGPT and BERT, which take structured input to produce coherent and relevant responses. Proper preprocessing helps in enhancing the model’s performance by enhancing its accuracy and efficiency, also improving generalization by removing noise, standardizing text,…
- Recurrent Neural Networks (RNNs) – Language ModelsWhat are RNNs (Recurrent Neural Networks) Recurrent Neural Networks, or RNNs, are variants of artificial neural networks. They have been designed for processing sequential data. Other than the conventional feed-forward neural networks, the connections in RNNs loop backward to themselves, which allows it to create and maintain memory of past inputs. This property makes RNNs…
- Simplifying Lemmatization in Text Processing – Complete Tutorial (with Programs)Introduction to Lemmatization in Text Processing Lemmatization in text processing is an important technique in natural language processing (NLP). Similar to stemming, lemmatization works to transform every word into its base or dictionary form known as lemma. For instance, “running” becomes “run,” “better” becomes “good,” and “children” becomes “child.” But lemmatization work differently than stemming.…
- Understanding and Implementing Stemming in Text ProcessingIntroduction to Stemming in Text Processing Stemming is one of the critical text pre-processing technique in Natural Language Processing (NLP) and for Large Language Models (LLMs). Stemming refers to a text processing technique that reduces inflected or derived words to their root or base form, known as the “stem.” To reduce the word to its…