
Natural Language Processing (NLP) is a technology in the artificial intelligence domain that involves interaction between human communication and machines understanding. It empowers machines to process human languages in a meaningful and useful way. It enables machines to learn & understand human languages and become capable to generate meaningful output. This makes it possible for easy and relevant human to machine communication.
Natural Language Processing (NLP) is possible with the combination of elements in human languages, computer science and machine learning. It involves processing of large volumes of linguistic data, which makes it fundamental for many applications related to data science and AI.
What is NLP (Natural Language Processing)?
Natural Language Processing (NLP) is a branch of artificial intelligence, which involves machine learning technologies and algorithms. Primary objective of NLP is to enable machines communication with human in human languages. For this NLP empowers machines to understand and generate text in multiple different human languages. NLP is at the center for applications such as speech recognition, machine translation, sentiment analysis, and chat-bots. NLP processes linguistic data based on the input’s syntax and semantics.
- Syntax focuses on the arrangement of words and phrases in the given sentence. This is useful to ensure the correctness of the sentence. It help machines to understand the different parts in the sentence and how each word relate to the another word. For example in the sentence, “The manager approved the project proposal,” syntax analysis would identify “manager” as the subject, “approved” as the verb, and “project proposal” as the object. This clarifies the grammar and role of each word in the given sentence.
- Semantics focuses on the meaning of each word and phrase in the sentence. It tries to understand the contextual meaning of the sentence and how the language interpret that information. For example – from the semantics of the sentence “The software update improved system efficiency,” it can interpreted that the software update positively effects the machine performance.
NLP is also used to transform raw-text data into structured format so that this information can be interpret by the machine learning models.
Key Techniques in NLP
The modern versions of Natural Language Processing make use of a number of techniques that can be categorized based on different approaches like rule-based, statistical approach, and deep learning-based approaches. Following are some of the techniques to natural language processing:
Text Processing
Text Processing is the initial step or preliminary step of Natural Language Processing. Most of the digital data collected from different sources, needs to be cleaned and structured to feed into the machine learning systems. Text processing technique involves cleaning, structuring and formatting of raw text data into a form that can be utilized by machine learning models. This process can include multiple steps like:
- Tokenization – Text is divided into words or tokens like for sentence “I Love Programming”, tokens can be “I”, “Love”, “Programming”.
- Word-level tokenization, where sentences are split into words.
- Sentence-level tokenization, where paragraphs are split into sentences.
- Stop-word removal – Removal of common words, such as “the” and “and”, which do not contribute to meaning.
- Removing punctuation and special characters
- Handling missing values (like empty cells in datasets)
- Stemming and Lemmatization – The process of reducing words to their root forms, such as “running” to “run”. This allows for the standardization of words with comparable meanings.
Bag of Words (BoW) and Term Frequency-Inverse Document Frequency (TF-IDF)
- Bag of Words (BoW) – This is a model representation of text as a set of words where grammar and order of words is of no concern. This model represents text data based on count of word occurrences. The Bag of Words (BoW) is a simple but effective model for lots of applications related to classification & clustering of words.
- Term Frequency-Inverse Document Frequency (TF-IDF) – This technique assigns weights to the words based on their frequency & importance in the text data. Rarity of the word across the whole text help to identify the importance of the word. Weight to the word is calculated by multiplying the frequency of a word in a text with the inverse frequency across text, highlighting rare but informative words.
Word Embeddings
Word embeddings are a type of word representation in natural language processing (NLP) that allows words to be represented in the form of real-valued continuous vectors in the multi-dimensional space, which carry semantic meanings.
- Word2Vec – The is an algorithm which trains a neural network to learn semantic relationships between of words. This also includes the context around the words.
- GloVe (Global Vectors) – The word vectors are built based on word co-occurrence statistics across a large corpus.
Sequence Models
Many of these applications in NLP deal with the sequential data. Traditional form of machine learning models similar to decision trees were not suitable for processing of sequential data. That is why more specialized models were developed.
- Recurrent Neural Networks (RNNs) are suitable for tasks where sequential data is involved. This keeps the context across word sequences.
- Long Short-Term Memory (LSTM) Networks are variants of RNNs. These networks help the model to keep more information for the longer sequences. These networks are very useful in applications related to text generation and translation.
- Attention Mechanisms gives the model ability to focus on specific parts of the input sequence. This helps to improves performance while working with longer texts.
Transformers
Transformers are the latest models used as modern NLP models. Transformers allow for parallel processing of text, which improves efficiency and performance.
- BERT (Bidirectional Encoder Representations from Transformers) – This is type of transformer model that reads text bidirectionally, allowing it to capture context better.
- GPT (Generative Pre-trained Transformer) – This model is known for its generative capabilities. These models are used in applications related to text generation and dialogue systems.
- T5 (Text-to-Text Transfer Transformer) – This model converts all NLP tasks into text-to-text format for flexibility in usage across many different types of NLP applications.
Steps in NLP Workflow
The common workflow of NLP (Natural Language Processing) would include the following steps:
- Data Collection and Preprocessing – This step involves multiple tasks like collection of raw text data, cleaning via tokenization, stop word removal, and lemmatization.
- Feature Extraction – In this step, text is converted into a machine-readable format using techniques like BoW, TF-IDF, or word embeddings.
- Model Training – RNN, LSTM, or Transformer like models are allowed to train on labeled datasets to learn different patterns in languages.
- Evaluation and Fine-tuning – In this stage model performance is evaluated. This also involves tuning of hyperparameters for the best results.
- Deployment – After complete training of the model, the trained model is ready to be deployed in production systems, where it can handle requests from the users and can handle real-world data.
How NLP Works – Audio-to-Text Text-to-Audio
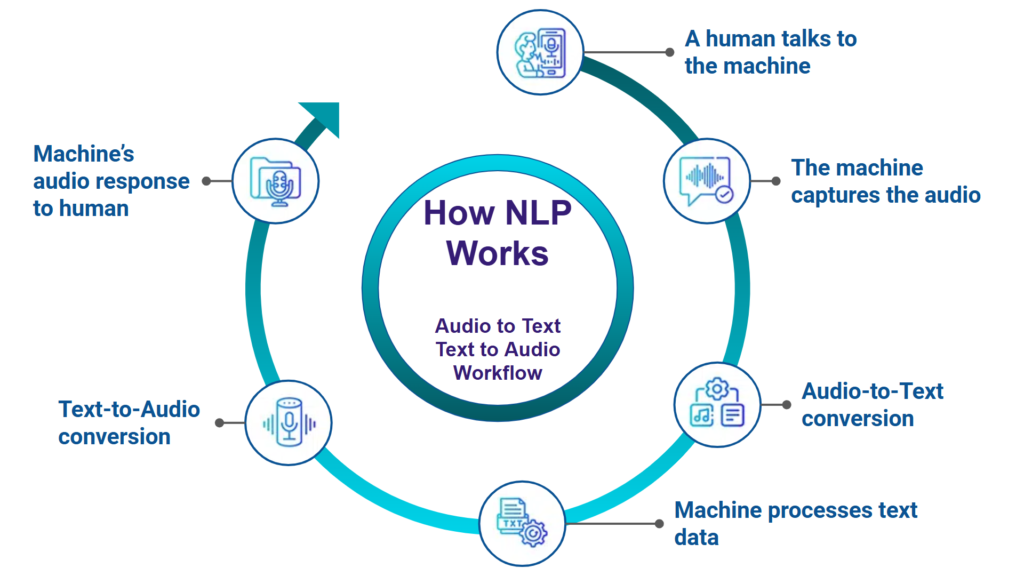
- A human talks to the machine
- The machine captures the audio
- Audio-to-Text conversion – Machine converts captured audio to text
- The machine processes converted text data and creates a text response
- Text-to-Audio – Text response is converted back to audio
- Machine respond with audio to human
Key Applications of NLP
Many applications of NLP can be found in different industries. Some of the applications of NLP are:
- Sentiment Analysis – This analysis is done to determine the opinion or expression represent by the given text. Opinion can be a positive, negative, or neutral. Sentiment analysis is popular and useful in public relations, analysis based on customer feedback and social media monitoring.
- Language Translation – This implies translation of text from one language into another. One prominent example is Google Translate.
- Chat-bots – NLP has its use cases in chat-bot applications. Chat-bots can answer the customers queries within the given context. For example – A banking application chat-bot can answer banking related queries.
- Virtual Assistants – NLP has been used in Virtual Assistants applications like Alexa, Siri, and Google Assistant. These applications can easily interpret the voice commands and can take required actions according to that.
- Text Summarization: NLP can be used to generate summaries from the large text documents or to generate summary (minutes of meeting) from an online meeting. This is useful for news summarization, legal document analysis, business meetings and more.
- Speech Recognition – This is used to convert voice (audio) language into written text. This is mainly used in applications like automated transcription and voice-activated systems.
Core Challenges in NLP
Natural Language Processing carries some unique challenges, including the following:
- Ambiguity – Some times words or phrases used in human language (sentences) can carry multiple meanings. With multiple meanings for the same word, it becomes extremely problematic for machines to understand the context accurately. For example, the word “bat” could refer to a flying mammal or it can also refer to a piece of sports equipment. Interpretation of this word will depend on the given context.
- Contextual Understanding – As human we sometimes use sentences, with the nuanced context, such as sarcasm, metaphors, or idioms. Humans intuitively understand the meaning of these sentences. In these scenarios, NLP models often struggle to understand the right context. For instance, the phrase “break a leg” is commonly used as a way to wish someone good luck, but a literal interpretation can be different which would miss the intended meaning.
- Domain-Specific Language – NLP models may not do so well on texts which uses domain-specific terminologies. These NLP models may require training very specific to a particular domain like law or medicine. For example certain terms involved in such cases could be legal terminologies, such as “habeas corpus” in law, or medical jargon, such as “tachycardia“, which a model trained on general language can misinterpret.
- Sparsity of Data – In many cases, getting larger datasets on particular language or domain can be a time-consuming and challenging task. This is particularly for unpopular languages or specialized domain studies. For instance, the data may not be easily available in the “space” domain.
Conclusion
In this article, we covered some basic concepts about NLP, like the definition and key techniques in NLP. We also described the very basics of text processing, such as BoW and TF-IDF, and more advanced topics, such as word embeddings, sequence models, and transformers. The general steps in NLP workflow were also discussed, including the role of NLP in both audio-to-text and text-to-audio tasks. Besides that, we also underlined several important applications of NLP, such as sentiment analysis and machine translation, examined the core challenges that still remain like ambiguity and context understanding.
Related Topics
- What are Large Language Models (LLMs)Large Language Models (LLMs) have become the new paradigm for interacting with technology in NLP-based applications. LLMs are taking the center stage in both understanding and generating human language, ranging from conversational chat-bots to graphics generation systems. This article covers what exactly LLMs are, focusing on their main attributes and importance in NLP. What are…
- What are N-Gram Models – Language ModelsN-Gram Models N-Gram models are a fundamental type of language model in Natural Language Processing (NLP). These models predict the probability of a sequence of words with regard to the previous word in a fixed window, referred to as “n.” These models have been used in simpler language-related tasks and provide the foundation for more…
- Recurrent Neural Networks (RNNs) – Language ModelsWhat are RNNs (Recurrent Neural Networks) Recurrent Neural Networks, or RNNs, are variants of artificial neural networks. They have been designed for processing sequential data. Other than the conventional feed-forward neural networks, the connections in RNNs loop backward to themselves, which allows it to create and maintain memory of past inputs. This property makes RNNs…