
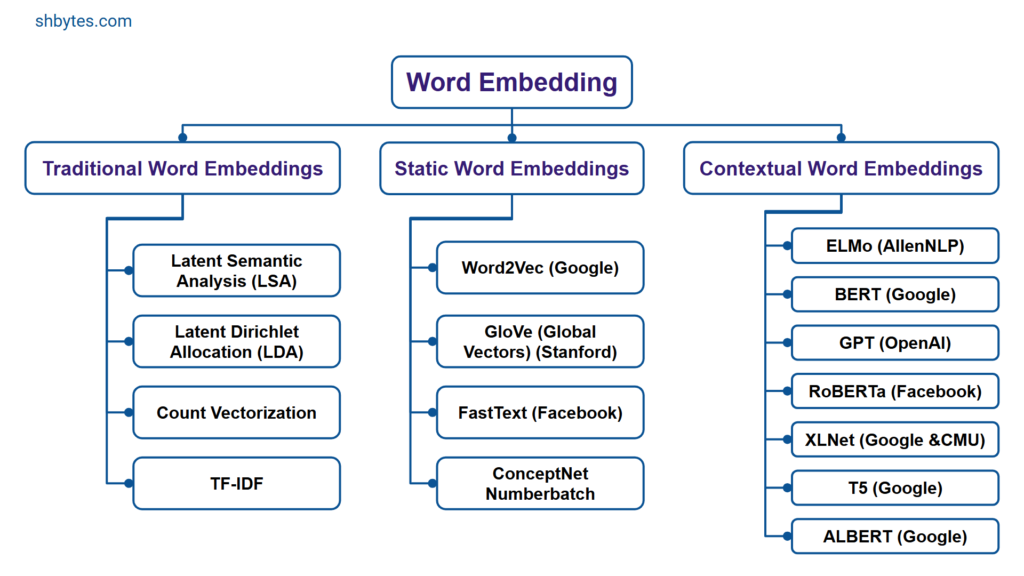
Static word embeddings is one of the approach to word representation in natural language processing (NLP). In this word embedding each word is represented as a single, fixed vector, independent of the context in which it was used. These word embeddings are the foundations of modern NLP.
Understanding Word Embeddings
Word embeddings are a type of word representation in natural language processing (NLP) that allows words to be represented in the form of real-valued vectors. Word embeddings are not like traditional encodings (one-hot encoding), where each word was represented as distinct entity or a unique binary vector. In word embeddings, words and documents are embedded using real value numbers positioned in multi-dimensional space. In this, words with similar meanings can have similar or near valued representations in a continuous vector space. This near value vector representation helps NLP models to work more efficiently. This reduces the problem of dimensionality and allows the models to learn relationships like synonym words having similar meaning and antonym words having opposite meanings.
Why Word Embeddings Are Useful
Word embeddings are very useful in NLP because of following reasons:
- Capture Semantic Similarity: Words with similar meanings or that are used in similar contexts will have similar vector embeddings. As an example, the words “king” and “queen” should be closer to each other in vector space compared to “king” and “car.”
- Efficient Large Vocabulary Handling: Since in the word embeddings, words are embedded into a continuous real-valued vector space, vocabulary takes very less storage and will be more memory efficient compared to traditional encoding (one-hot encoding).
- Transfer Learning: Pre-trained embeddings can be fine tuned for specific tasks. This provides better and faster performance, specially in scenarios where training data is limited.
Word Embeddings Techniques
There are various techniques to create word embeddings, from early methods like Word2Vec and GloVe to modern transformer-based embeddings.
Word2Vec
Word2vec technique was first developed by researchers at Google in 2013. This was one of the earliest and effective technique for word embeddings. It represents each word as a vector such that semantically similar words will be mapped into nearby points in the vector space.
How Word2Vec Works
Word2Vec uses a shallow neural network and has two key architectures:
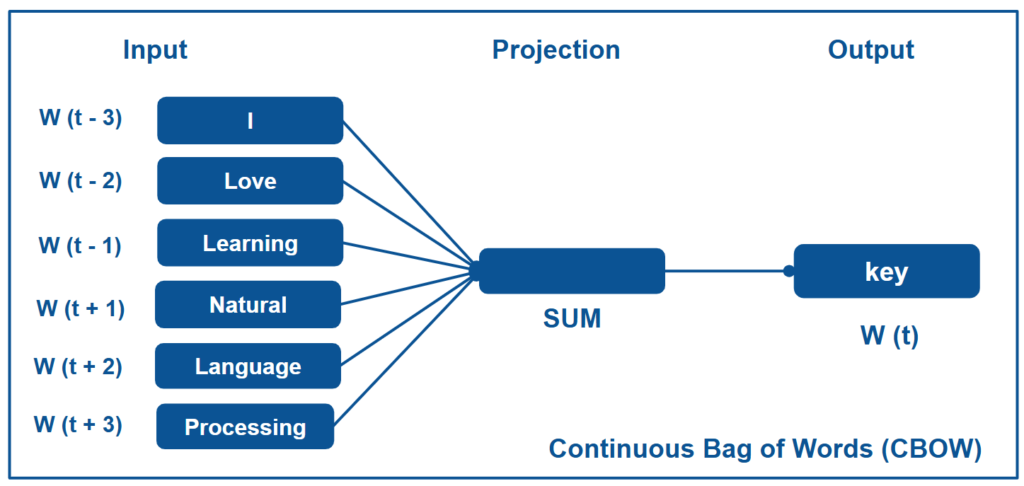
- Continuous Bag of Words (CBOW): This architecture is used to predict the next target word based on the near-by contextual words. Continuous Bag of Words (CBOW) is very efficient and suitable for large datasets.
- Skip-Gram: This architecture is used to predict the near-by words or surrounding contextual words based on the target word. Skip-Gram works best with smaller datasets by observing the relationship if every single word.
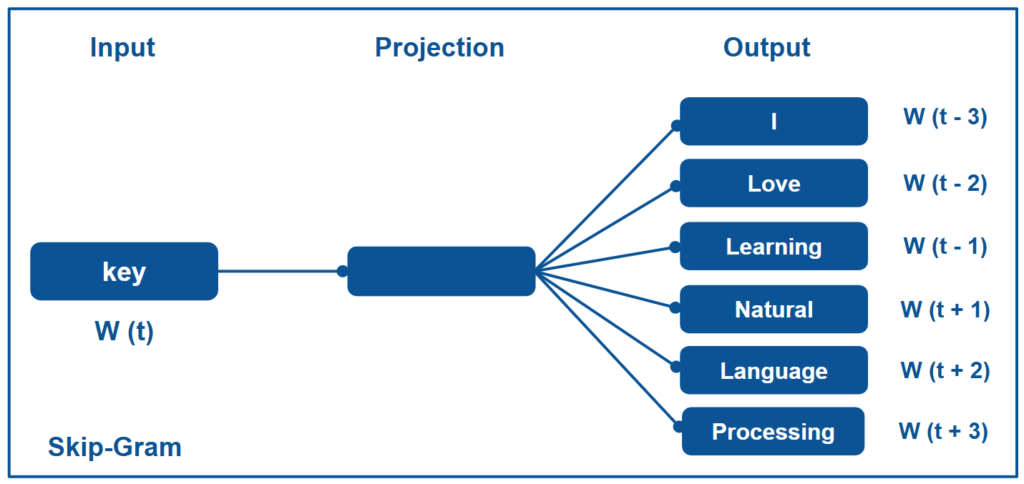
Each of these architectures is trained either by using negative dataset or hierarchical softmax so as to optimize the network for high-quality word vectors.
Key Characteristics of Word2Vec
- It captures semantic relationships like synonyms, antonyms or analogies e.g., king – man + woman ≈ queen.
- Using this technique, models can be trained on large datasets quickly, making it efficient for real-world applications.
Example Code for Word2Vec
from gensim.models import Word2Vec
import nltk # nltk Python library
from nltk.tokenize import word_tokenize, sent_tokenize
nltk.download('punkt_tab') # download punkt_tab library
# Given text
text = "Tokenization in a major technique in NLP. Word embeddings help models learn languages"
# Word tokenization
word_tokens = word_tokenize(text) # Use method word_tokenize to get word tokens
# Train the Word2Vec model
skipgram_model = Word2Vec(sentences=[word_tokens],
vector_size=50, # Dimensions of the word vectors
window=5, # Maximum distance between the current and predicted word within a sentence
min_count=1, # Ignores all words with a total frequency lower than this
sg=1) # Skip-Gram model (1 for Skip-Gram, 0 for CBOW)
# Get the embedding for a specific word
vector = skipgram_model.wv['NLP']
print("Embedding for 'NLP':", vector)
# Finding similar words
similar_words = skipgram_model.wv.most_similar("NLP")
print("Words similar to 'NLP':", similar_words)Output:
# Output
# Embedding for 'NLP': [-0.01427803 0.00248206 -0.01435343 -0.00448924 0.00743861 0.01166625
# 0.00239637 0.00420546 -0.00822078 0.01445067 -0.01261408 0.00929443
# -0.01643995 0.00407294 -0.0099541 -0.00849538 -0.00621797 0.01131042
# 0.0115968 -0.0099493 0.00154666 -0.01699156 0.01561961 0.01851458
# -0.00548466 0.00160045 0.0014933 0.01095577 -0.01721216 0.00116891
# 0.01373884 0.00446319 0.00224935 -0.01864431 0.01696473 -0.01252825
# -0.00598475 0.00698757 -0.00154526 0.00282258 0.00356398 -0.0136578
# -0.01944962 0.01808117 0.01239611 -0.01382586 0.00680696 0.00041213
# 0.00950749 -0.01423989]
# Words similar to 'NLP': [('major', 0.2373521625995636), ('.', 0.1845843642950058), ('learn', 0.13940522074699402), ('help', 0.10704469680786133), ('a', 0.04550706967711449), ('models', -0.010117169469594955), ('in', -0.0560765378177166), ('Tokenization', -0.06485531479120255), ('Word', -0.08925073593854904), ('embeddings', -0.10186848789453506)]GloVe (Global Vectors for Word Representation)
GloVe (Global Vectors for Word Representation) is another popular word embedding technique. This technique was developed by researchers at Stanford University. GloVe technique creates word vectors based on the global statistical information of words across a corpus. It uses word re-usability matrices, which calculate how frequently a pairs of words appear together across the whole text. It does not look at each contextual information (as it was done in Word2Vec).
How GloVe Works
GloVe constructs its embeddings by studying word co-occurrence statistics on a global scale. There are multiple steps followed to work with the GloVe embedding.
Building a Word Co-occurrence Matrix
The GloVe embedding starts by creating a word co-occurrence matrix from a large dataset. This matrix counts the frequency of each word for every other word that appears within a certain context window. Each entry in the matrix, Xij, represents the frequency of word Wi appears given that another word Wj has already occurred. This co-occurrence information gives a global statistical view of the relationships between words. For example:
- If “king” and “queen” often appear together, their co-occurrence value in the matrix will be high.
- If “rabbit” and “elephant” rarely appear together, their co-occurrence value will be low.
The Probability Ratio
GloVe embedding focuses on the ratios of co-occurrence probabilities that carry much meaningful relationships between words. For instance, the relationship between words like “man,” “woman,” “king,” and “queen” can be expressed through their co-occurrence patterns.
The GloVe Objective Function
GloVe optimizes an objective function to create word embeddings. The purpose of this function is to minimize the difference between the dot product of two word vectors and the logarithm of their co-occurrence frequency.
The Weight Function f(Xij)
The purpose of weight function f(Xij) in GloVe embedding is to ensure that:
- The words with very high or very low co-occurrence frequency does not disrupt the learning process.
- The model focuses more on word pairs with a medium level of co-occurrence, which generally provides more informative relationships.
Optimize the Model
To optimize the GloVe embedding, its algorithm uses an objective function and gradient descent to learn the word vectors for each word in the vocabulary. Purpose of this optimization is to gather global statistical information about each word co-occurrences, which enables the embeddings to encode semantic relationships.
Resulting Embeddings
After GloVe embeddings training, each word is stored as a real-valued dense vector in a high-dimensional space, which includes semantic properties encoded in vector arithmetic. Then we can use the GloVe embeddings to get the relationship such as: vector("king") - vector("man") + vector("woman") ≈ vector("queen"). This illustrates that the model has captured meaningful relationships between words.
Key Characteristics of GloVe
- GloVe embeddings incorporate both local context and global co-occurrence, which results in richer representation of word combinations.
- GloVe provides pre-trained embeddings that can be directly used or fine-tuned for specific tasks.
Example Code for GloVe
Download the GloVe Embeddings before start using it in your code.
import numpy as np
# Load pre-trained GloVe embeddings (downloaded from a source)
embedding_dict = {}
# Download GloVe enbeddings from https://nlp.stanford.edu/projects/glove/
with open("glove.6B.100d.txt", encoding="utf8") as f: # Read embeddings as key-value pair dictionary
for line in f:
values = line.split()
word = values[0]
vector = np.asarray(values[1:], "float32")
embedding_dict[word] = vector
# Accessing the embedding for a specific word
print("Embedding for 'language':", embedding_dict.get("language"))
# Calculating similarity between words
def cosine_similarity(vec1, vec2):
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
similarity = cosine_similarity(embedding_dict["king"], embedding_dict["queen"])
print("Cosine similarity between 'king' and 'queen':", similarity)Output
# Output
# Embedding for 'language': [ 0.18519 0.34111 0.36097 0.27093 -0.031335 0.83923 -0.50534
# -0.80062 0.40695 0.82488 -0.98239 -0.6354 -0.21382 0.079889
# -0.29557 0.17075 0.17479 -0.74214 -0.2677 0.21074 -0.41795
# 0.027713 0.71123 0.2063 -0.12266 -0.80088 0.22942 0.041037
# -0.56901 0.097472 -0.59139 1.0524 -0.66803 -0.70471 0.69757
# -0.11137 -0.27816 0.047361 0.020305 -0.184 -1.0254 0.11297
# -0.79547 0.41642 -0.2508 -0.3188 0.37044 -0.26873 -0.36185
# -0.096621 -0.029956 0.67308 0.53102 0.62816 -0.11507 -1.5524
# -0.30628 -0.4253 1.8887 0.3247 0.60202 0.81163 -0.46029
# -1.4061 0.80229 0.2019 0.60938 0.063545 0.21925 -0.043372
# -0.36648 0.61308 1.0207 -0.39014 0.1717 0.61272 -0.80342
# 0.71295 -1.0938 -0.50546 -0.99668 -1.6701 -0.31804 -0.62934
# -2.0226 0.79405 -0.16994 -0.37627 0.57998 0.16643 0.1356
# 0.0943 -0.24154 0.7123 -0.4201 0.24735 -0.94449 -1.0794
# 0.3413 0.34704 ]
# Cosine similarity between 'king' and 'queen': 0.750769FastText
FastText is an extension of the Word2Vec model. This was developed by Facebook’s AI Research (FAIR) team. This embedding uses subword (character n-grams) information to improve over traditional word embeddings. Subword information helps it to handle rare or out-of-vocabulary words more effectively. FastText embedding is more useful for languages with complex morphology, where words generally have multiple forms.
How FastText Works
Instead of taking each word as a single entity, FastText breaks down each word into n-grams forms of its subwords. For example, “word” can be represented as “w”, “wo”, “wor”, “ord”. By breaking words into these n-grams, FastText is able to create embeddings for words which it was not able to get in the training data.
Key concepts for FastText working
- Subword Tokenization: Unlike Word2Vec and GloVe embeddings, that treat each word as an atomic unit, FastText breaks each word into a smaller units known as subwords or character n-grams. For example, the word “apple”, can be break down into trigrams or three-character chunks like
<ap,app,ppl,ple,le>. Here<and>symbol represents the beginning and the end of the word, respectively. FastText can sum the embeddings of these character n-grams, to represent the word “apple”. - Optimize Memory Usage: This character n-grams embedding representation, helps it to optimize the memory usage as well. FastText to better generalize words with similar structures like “apple” and “apples” can use the similar embeddings.
- Handling Rare and Out-of-Vocabulary Words: Because FastText uses subwords or character n-gram embedding technique, it can create new words combining sub-tokens. This makes it possible to generate embeddings for words that was not given as part of its training or out-of-vocabulary words. For example, word “unbelievable” embeddings can be generated by combining the n-gram embeddings for “un,” “believe,” and “able.” This helps FastText in tasks related to spelling corrections, correcting typos, or different language handling.
- Training Process: FastText training process is very similar to Word2Vec embedding training process. It’s training process has two main components:
- CBOW (Continuous Bag of Words): This is used to predict the next or target word based on given context. This is much faster and better with larger datasets.
- Skip-Gram Model: This is used to predict the near words based on the given target word. This works better with smaller datasets and good at capturing word-to-word relationships.
- Embedding Composition: FastText’s final embedding for a word is computed by taking the average (or sum) of all its subword or character n-gram embeddings. This way model can use both the word’s full representation and the subword patterns, representing both local (within the word) and global (within the language) structure.
Example Code for FastText
from gensim.models import FastText
import nltk # nltk Python library
from nltk.tokenize import word_tokenize, sent_tokenize
nltk.download('punkt_tab') # download punkt_tab library
# Given text
text = "Tokenization in a major technique in NLP. Word embeddings help models learn languages"
# Word tokenization
word_tokens = word_tokenize(text) # Use method word_tokenize to get word tokens
# Train FastText model
model = FastText(sentences=word_tokens,
vector_size=50, # Dimensions of the word vectors
window=3, # Maximum distance between the current and predicted word within a sentence
min_count=1) # Ignores all words with a total frequency lower than this
# Get embedding for a word
vector = model.wv['NLP']
print("Embedding for 'NLP':", vector)
# FastText can generate embeddings for out-of-vocabulary words
oov_vector = model.wv['NLPlang']
print("Embedding for 'NLPlang':", oov_vector)Output
# Embedding for 'NLP': [ 6.7112967e-04 -5.7537104e-03 -3.8209217e-04 1.8261531e-03
# -4.3684859e-03 -2.1409548e-03 -4.6887714e-04 3.7225138e-03
# -4.4143177e-03 -6.5339045e-03 -6.6128164e-03 1.6831801e-03
# -2.9464439e-03 8.4889242e-03 9.8627678e-04 -1.1673558e-02
# 7.0546214e-03 1.0250329e-02 -3.7461389e-03 2.2268505e-03
# -5.7210624e-03 -6.2403362e-03 -6.7902668e-03 -7.2669764e-03
# 3.5307240e-03 8.6204302e-05 1.4065602e-03 -2.6211115e-03
# 4.1991104e-03 1.6430151e-03 -8.8640861e-03 -4.2608319e-04
# -2.8893941e-03 -8.8902814e-03 8.5078767e-03 8.2775457e-03
# -1.3053512e-03 -7.5113936e-03 -6.6510378e-04 -5.4182769e-03
# -1.8815467e-03 -1.6216278e-03 -4.9716611e-03 -1.7002182e-03
# -2.9542008e-03 -5.1571857e-03 -2.6930883e-04 3.6215771e-03
# 1.0876763e-03 -4.1648340e-03]
# Embedding for 'NLPlang': [-4.45177453e-03 2.80638388e-03 -2.81983591e-03 1.83598965e-03
# -9.30043927e-04 6.45409513e-04 1.56107056e-03 -1.67246442e-04
# 1.18434546e-04 8.74134188e-04 -1.01212325e-04 -3.30892578e-03
# 1.03953527e-03 2.51525576e-04 2.34705932e-03 1.38890883e-03
# -5.85419533e-04 6.07060315e-03 -1.47976016e-03 1.72582723e-03
# 2.58205528e-03 -5.39712422e-03 -2.09404016e-03 -4.82992531e-04
# 7.34058442e-04 8.99983497e-05 2.25677999e-04 -2.43995848e-04
# -1.77256425e-03 2.61991314e-04 1.97137496e-03 -2.31975014e-03
# 2.54085008e-03 7.32400105e-04 9.11888725e-04 6.78675307e-04
# -2.13333569e-03 -1.84630568e-03 1.05537695e-03 9.96632152e-04
# 1.53413892e-03 -3.52063309e-03 4.74144612e-03 -2.25093812e-04
# -4.46041767e-03 1.32573955e-03 1.13292388e-03 -1.61171251e-03
# 1.69862364e-03 8.82553868e-04]Comparing Word2Vec, GloVe, and FastText
| Model (Embedding) | Key Feature | Pros | Cons |
|---|---|---|---|
| Word2Vec | Learns from local context, Continuous Bag of Words (CBOW) & Skip-Gram | Efficient, captures word relationships | Static embeddings (no context) |
| GloVe | Global word co-occurrence | Captures global context effectively | May struggle with rare words |
| FastText | Uses character n-grams for each word, Continuous Bag of Words (CBOW) & Skip-Gram | Effective for out-of-vocabulary and morphologically rich languages | More complex model |
Applications of Static Word Embeddings
Static word embeddings are the foundation for modern NLP applications. These were widely used before advancement in contextual embeddings. But still static word embeddings are valuable in many NLP applications, especially where context is not very important or entirely not needed. Common applications include:
- Text Classification – In text classification tasks like sentiment analysis, topic categorization etc., static word embeddings are used to represent words in a document. Example, word embeddings are used to classify customer reviews into positive, neutral, or negative categories.
- Named Entity Recognition (NER) – Named Entity Recognition (NER) is generally the process of determining specific entities within text, such as a person’s name, an organization, location, and date. Pretrained static embeddings have a baseline that can recognize common names of entities and terms related to those entities after fine-tuning with annotated data. Example: cities, countries and companies names have been extracted from news articles facilitated by static embedding combined with an NER model.
- Language Translation – These static embeddings represent words in the different languages and help the language translation model align similar meanings across different languages. Example: Train a model to translate simple phrases from/to English/Spanish using word embeddings by aligning vocabulary similarities. Google translation is one of the practical application for this use case.
- Document Similarity and Recommendations – Static embeddings can be used to create similar documents. Example: to cluster articles on similar topics for recommendation systems on news aggregators or academic research platforms.
- Information Retrieval and Search – Word embeddings allow search engines to look beyond simple keywords matching by comprehending semantic similarities between search queries and document contents, thus allowing them to retrieve relevant documents even in the absence of exact keywords, thereby increasing the quality and relevance of the search results. For instance, this may be utilized in a customer support portal to extend search capabilities and return relevant articles even when users do not use the exact keywords.
- Question Answering – Word embeddings provide a base representation of questions and answers in QA tasks. Example: Most of the commonly asked questions in an FAQ system find their answer by matching question embeddings to answer embeddings.
- Text Summarization – Word embeddings can be used for text summarization. Example: Summarizing long articles by selecting key sentences based on similarity to main topics or overall document theme. It can also be used to create Minutes-of-meetings by combining summarization with voice to text.
Conclusion
Traditional word embeddings have been very instrumental in taking forward the field of NLP through Word2Vec, GloVe, and FastText. These embeddings are efficient and meaningful representations of words that allow semantic analysis, similarity detection, and the understanding of languages; therefore, they constitute a necessary ingredient in applications ranging from text classification to sentiment analysis and beyond. Even with newer embeddings that are context-aware in use today, traditional embeddings remain highly effective for many tasks and therefore continue to provide strong fundamentals in NLP.
LLM code snippets and programs related to Word Embeddings in NLP, can be accessed from GitHub Repository. This GitHub repository all contains programs related to other topics in LLM tutorial.
Related Topics
- Understanding Sentence and Document Embeddings in NLPWhat is Sentence and Document Embeddings Sentence and document embeddings are at the core of Natural Language Processing (NLP). These embeddings are represented in a close real-valued vectors format and are created in such a way that these contains the meaning of the whole sentences, paragraphs, or documents. Word embeddings were able to express meaning of single…
- Understanding Static Word Embeddings in NLP – A Complete GuideStatic word embeddings is one of the approach to word representation in natural language processing (NLP). In this word embedding each word is represented as a single, fixed vector, independent of the context in which it was used. These word embeddings are the foundations of modern NLP. Understanding Word Embeddings Word embeddings are a type…
- Natural Language Processing (NLP) – Comprehensive GuideNatural Language Processing (NLP) is a technology in the artificial intelligence domain that involves interaction between human communication and machines understanding. It empowers machines to process human languages in a meaningful and useful way. It enables machines to learn & understand human languages and become capable to generate meaningful output. This makes it possible for…
- Recurrent Neural Networks (RNNs) – Language ModelsWhat are RNNs (Recurrent Neural Networks) Recurrent Neural Networks, or RNNs, are variants of artificial neural networks. They have been designed for processing sequential data. Other than the conventional feed-forward neural networks, the connections in RNNs loop backward to themselves, which allows it to create and maintain memory of past inputs. This property makes RNNs…
- What are N-Gram Models – Language ModelsN-Gram Models N-Gram models are a fundamental type of language model in Natural Language Processing (NLP). These models predict the probability of a sequence of words with regard to the previous word in a fixed window, referred to as “n.” These models have been used in simpler language-related tasks and provide the foundation for more…