
N-Gram Models
N-Gram models are a fundamental type of language model in Natural Language Processing (NLP). These models predict the probability of a sequence of words with regard to the previous word in a fixed window, referred to as “n.” These models have been used in simpler language-related tasks and provide the foundation for more advanced models. These models help by offering insight into patterns of words and sequences in language.
What is N-Gram?
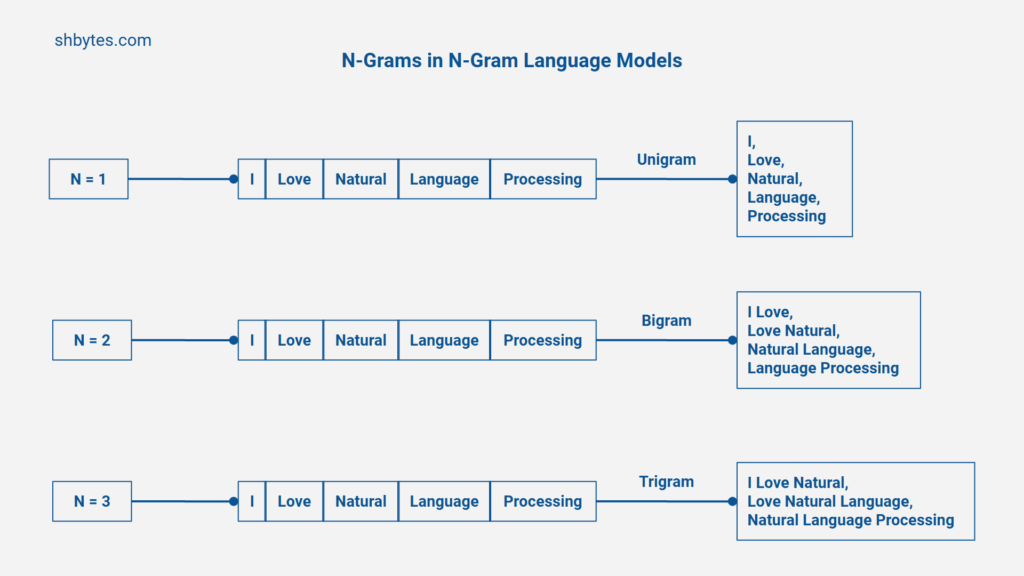
The n-gram refers to a continuous sequence of n-words from the given text. In a sequence, every word or token is considered based on its preceding words. For example – for the given sentence “I love natural language processing.” Let’s see how n-gram models (unigram, bigram, and trigram) would process and analyze this sentence.
- Unigrams are => “I”, “love”, “natural”, “language”, “processing”.
- Bigrams are => “I love”, “love natural”, “natural language”, “language processing”
- Trigrams are => “I love natural”, “love natural language”, “natural language processing”.
Unigram Model (1-Gram)
A unigram model treats each word as an independent unit of information. It does not consider the word order or the related words around it. It only considers the individual probability of each word appearing in the given sentence.
For example in the sentence “I love natural language processing”, the unigrams are => “I”, “love”, “natural”, “language”, “processing”.
The probability of each word in this unigram model is calculated based on the frequency of each word divided by the total number of words in the training dataset. Each word is independent on its own, without depending on any other word.
P(w1, w2, w3,… wn) = P(w1) × P(w2) × ⋯ × P(wn)
The probability of the sentence “I love natural language processing” using a unigram model would be:
P("I love natural language processing") = P("I") ⋅ P("love") ⋅ P("natural") ⋅ P("language") ⋅ P("processing")
Bigram Model (2-Gram)
In a bigram model, each word depends on the previous word. It considers pairs of consecutive words and calculates the probability of each word based on the previous word.
For example in the sentence “I love natural language processing”, the bigrams are => “I love”, “love natural”, “natural language”, “language processing”.
The probability of the sentence “I love natural language processing” using a bigram model would be:
P("I love natural language processing") = P("I") ⋅ P("love" | "I") ⋅ P("natural" | "love") ⋅ P("language" | "natural") ⋅ P("processing" | "language")
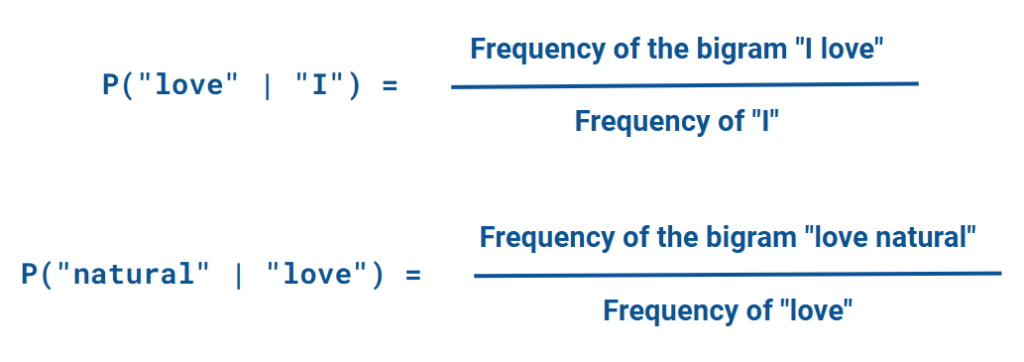
Each bigram probability, such as P("love" | "I"), would be calculated by dividing the frequency of the bigram “I love” by the frequency of “I” in the training data.
P("natural" | "love"), would be calculated by dividing the frequency of the bigram “love natural” by the frequency of “love” in the training data.
Trigram Model (3-Gram)
In a trigram model, each word depends on the two previous words. This adds more context but also requires more data to estimate accurately. For our example sentence, the trigrams are => “I love natural”, “love natural language”, “natural language processing”.
The probability of the sentence using a trigram model would be:
P("I love natural language processing") = P("I") ⋅ P("love" | "I") ⋅ P("natural" | "I love") ⋅ P("language" | "love natural") ⋅ P("processing" | "natural language")
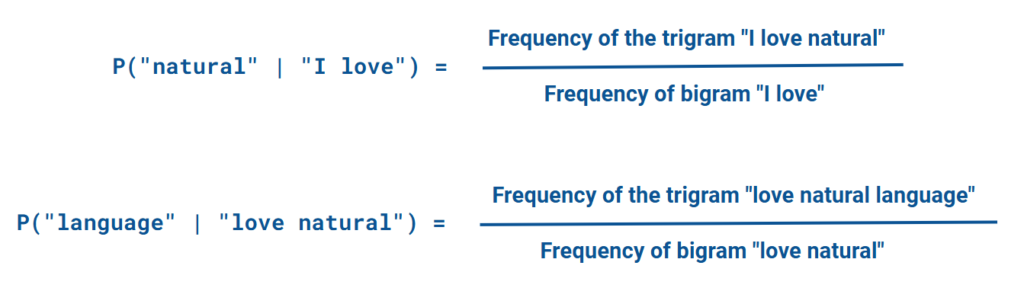
Each trigram probability, such as P("natural" | "I love"), would be calculated by dividing the frequency of the trigram “I love natural” by the frequency of the bigram “I love.”
Each trigram probability, such as P("natural" | "I love"), would be calculated by dividing the frequency of the trigram “I love natural” by the frequency of the bigram “I love.”
P("language" | "love natural"), would be calculated by dividing the frequency of the trigram “love natural language” by the frequency of the bigram “love natural.”
N-Gram Probabilities
- Unigrams capture individual word frequencies, ignoring sequence.
- Bigrams capture the relationship between each word and the previous one.
- Trigrams capture relationships involving two preceding words, allowing for more context.
- N-gram captures relationship involving
n-1preceding words, wherencan be any integer.
The more context (i.e., higher n), the better the model understands word relationships, though it also requires more data to avoid sparsity issues.
How N-Gram Models Work
N-gram models work based on the probability estimation of a word in a sequence based on the previous n-1 words. For example, in a bigram model, the probability of a word only depends on the previous word; in a trigram model, it depends on the previous two words.
For a given sequence of words w1, w2,…,wn, the probability of the sequence in an n-gram model is calculated as:
P(w1, w2, …, wn) = P(w1) ⋅ P(w2∣w1) ⋅ P(w3∣w1,w2) ⋯ P(wn∣wn−1,…,wn−(n−1))
In simpler terms, each word’s probability is calculated based on the preceding n-1 words rather than the entire sentence.
Training an N-Gram Model
Follow the given steps to train an n-gram model:
- Count N-Grams – Count the frequency of each n-gram in the training text. For a bigram model, count how often each pair of words occurs.
- Calculate Probabilities – Use these counts to estimate the probabilities of each n-gram. For bigrams, this is done by dividing the count of each bigram by the count of the preceding word.
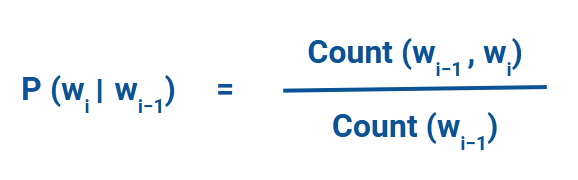
P(wi∣wi−1) = Count(wi−1,wi)/Count(wi−1)
Characteristics of N-Gram Models
Strengths of N-Gram Models
- Simplicity – N-Grams are easily understandable, and their models implementation and training are easy with minimum computation.
- Efficiency – Suitable for practical applications involving relatively small or medium-sized data sets.
- Interpret-ability – Probabilities are straightforward and hence easier to reason about the behavior of the model.
Limitations of N-Gram Models
- Limited Context – N-grams only consider the last
n-1words, thus failing to capture long-range dependencies, which are crucial when understanding complex language patterns and context. - Data Sparsity – As
nincreases, the model needs exponentially more data to estimate probabilities accurately. This often causes the sparsity issue while training the model, as many possible n-grams will not appear in the training data. - High Memory Usage – Large datasets, or larger values of n, will see a significant increase in memory and storage requirements because most n-gram counts will need to be kept in memory.
Applications of N-Gram Models
Despite simplicity and limitations, n-gram models still have several uses in various tasks especially where data sizes and computational resources are limited:
- Spell Checking – Check of most common word pairs can be performed and their accurate spellings can be predicted.
- Basic Text Prediction – The given task is to predict the next word, with applications in autocomplete systems.
- Machine Translation – Provide models for baseline translations of phrases.
- Speech Recognition – Small contexts are used to predict likely words in spoken language.
Conclusion
N-gram models are one of the earliest approaches to language modeling. It shows the easiest way in which the statistical analysis on sequences of words can be used in order to predict or generate text. Limited by their simplistic assumptions, n-grams have set the stage for more advanced models by showing how language patterns can be quantified and then utilized in applications involving NLP.
Related Topics
- What is Tokenization in NLP – Complete Tutorial (with Programs)What is Tokenization Tokenization is one of the major technique in Natural Language Processing (NLP) preprocessing that basically converts raw text into smaller, structured and organized units called tokens. These tokens can be words, subwords, sentences, or even characters. The size of tokens would depend on what form of processing is in view. Why Tokenization Matters in NLP Tokenization is important because Natural Language Processing (NLP) models cannot process texts without breaking it down into some form…
- What are Large Language Models (LLMs)Large Language Models (LLMs) have become the new paradigm for interacting with technology in NLP-based applications. LLMs are taking the center stage in both understanding and generating human language, ranging from conversational chat-bots to graphics generation systems. This article covers what exactly LLMs are, focusing on their main attributes and importance in NLP. What are…
- Natural Language Processing (NLP) – Comprehensive GuideNatural Language Processing (NLP) is a technology in the artificial intelligence domain that involves interaction between human communication and machines understanding. It empowers machines to process human languages in a meaningful and useful way. It enables machines to learn & understand human languages and become capable to generate meaningful output. This makes it possible for…