
What is Tokenization
Tokenization is one of the major technique in Natural Language Processing (NLP) preprocessing that basically converts raw text into smaller, structured and organized units called tokens. These tokens can be words, subwords, sentences, or even characters. The size of tokens would depend on what form of processing is in view.
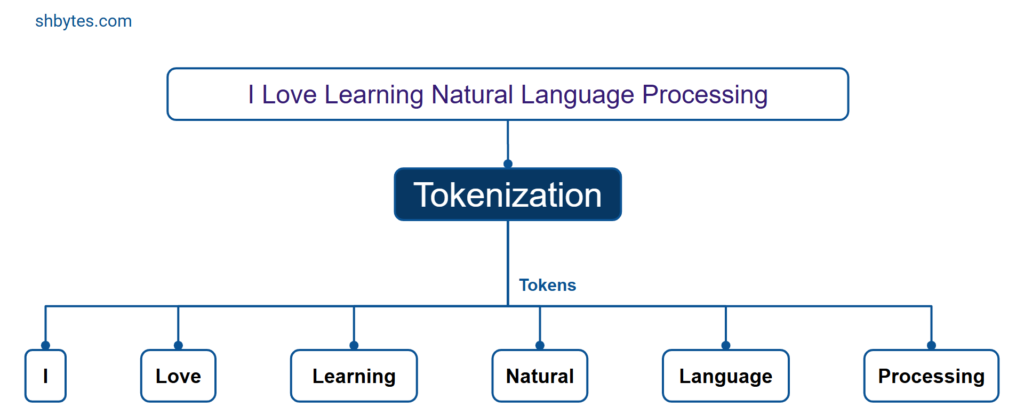
Why Tokenization Matters in NLP
Tokenization is important because Natural Language Processing (NLP) models cannot process texts without breaking it down into some form of manageable unit that machine can understand and analyze it. In their raw form, text data are just a stream of characters and words which are in human language and can be understood by humans only. It is through tokenization that the text gets broken down into discrete units (called tokens) that any machine learning model could understand. Because of this it becomes possible to solve more complex NLP tasks such as sentiment analysis, machine translation, and text summarization. Proper tokenization allows the models to capture word boundary, handle out-of-vocabulary terms, and perform sentence processing.
Types of Tokenization
Word Tokenization
Word tokenization splits the text into individual words based either on white-space, punctuation, or specific patterns. It is the most straightforward approach and is commonly used for tasks that operate at the word level, like word frequency analysis, spelling correction, meaning of words or word embeddings.
How Word Tokenization Works
During word tokenization, a text string is split based either on white-space, punctuation, or specific patterns. This split of text also depends on the language and the context given for the analysis. For example:
Input: "I love learning Natural Language Processing."
Output: ["I", "love", "learning", "Natural", "Language", "Processing]
Input: "Tokenization is important for NLP."
Output: ["Tokenization", "is", "important", "for", "NLP"]In this example, each word and punctuation mark is taken as a separate token. But based on application requirements, punctuation tokens may be excluded, included or can be used in other ways.
Techniques for Word Tokenization
- Whitespace Tokenization: This is the most basic form, where text is split by whitespace. This method does not consider punctuation, contractions, parenthesis, abbreviations or special cases. This is suitable and works well for basic tasks.
- Rule-Based Tokenization: This technique applies specific rules to handle punctuation, contractions, or hyphenated words. For example, “don’t” should be separated into “do” and “n’t”.
- Library or Model Based Tokenization: Libraries such as NLTK, SpaCy, and Hugging Face Transformers & ML models provide advanced pre-trained tokenizers. These libraries and models are able to handle complex cases from different languages.
- Subword Tokenization: This tokenization technique is used in language models like BERT and GPT. It splits words into smaller units (subwords) according to the word frequency counts, that allow handling of unknown words and variations. For example word “unhappiness” can be split into “un,” “happi,” and “ness.”
Sentence Tokenization
Sentence tokenization, also known as sentence segmentation. Sentence tokenization is the process of dividing texts into sentences. This type of tokenization is useful for tasks like machine translation, summarization, named entity recognition, and sentiment analysis. In all these tasks unit of meaning often resides at the sentence level.
How Sentence Tokenization Works
Input: "What is tokenization in NLP. What are the different types of tokenization."
Output: ["What is tokenization in NLP.", "What are the different types of tokenization."]
Input: "Tokenization is essential. It improves NLP model performance."
Output: ["Tokenization is essential.", "It improves NLP model performance."]Generally, sentence tokenization is based on punctuation and sentence-ending markers, such as periods, exclamation points, and question marks. But it is not quite that simple because of the following reasons:
- Abbreviations: Words such as “Dr.”, “e.g.”, or “U.S.” are followed by periods but aren’t sentence endings.
- Quotation Marks and Parentheses: Sentences might end with quotation or parentheses, which makes it tricky to detect where the major sentence ends.
- Complex Sentence Structures: Languages like English can employ punctuation marks, like semicolon or commas separating several clauses but without denoting the start of new sentence or end of sentence.
Techniques for Sentence Tokenization
- Rule-Based Approach: To identify the boundaries of sentences, different predefined rules or regular expressions are used. These rules can be different for different languages. For example, in English language a rule might say that a comma, semi-colon are not end of sentence OR a rule for abbreviations like U.S. can be, a period followed by a capital letter is not end of sentence
- Machine Learning Models: Some sentence tokenizers rely on machine learning or NLP models trained on large datasets to identify sentence boundaries. These models can recognize patterns in the text and predict sentence boundaries based on context rather than just on simple punctuation.
- Libraries and Tools: Most NLP libraries, like NLTK (Natural Language Toolkit), spaCy, and Stanford NLP, have strong sentence tokenizers, which handle a wide range of text patterns, abbreviations, and special cases.
Subword Tokenization
Subword tokenization is a major technique in NLP for text representation that involves breaking down words into smaller units, known as “subwords“. This technique is not similar to word tokenization technique in which whole word is considered as a token. Sometimes in languages we have out-of-vocabulary words like local language words or jargons. This technique is helpful to handle those out-of-vocabulary words and increases the flexibility of the language model to handle wide range of words by combining subwords. This technique is very useful in transformer-based models like BERT and GPT.
Input: "unhappiness"
Output: ["un", "##happi##", "ness"]
Input: "Subword Tokenization is essential."
Output: ["Sub", "##word", "Token", "##ization", "is", "essential"]The helps language model to learn that “un” and “ness” are common prefixes and suffixes, which allows combining these prefixes & suffixes to interpret words like “unhappy” or “happiness”.
How Subword Tokenization Works
Some of the most frequently used approaches for subword tokenization are Byte-Pair Encoding (BPE), WordPiece, and SentencePiece.
- Byte-Pair Encoding (BPE) – BPE begins by taking each character as a token and then iteratively merges pairs of adjacent characters with most frequently appearing sub-words. For example, it may start with “bananas” as “
b a n a n a s” and then start merging them into “ban an as“. - WordPiece – This approach is used by models like BERT. This approach also starts with a character based vocabulary and then perform iterative mergers on the subwords using a probabilistic model. Its objective is to optimize the vocabulary by using fewer tokens as possible. It tries to achieve optimal balance between the number of token in the vocabulary and their frequency. By doing so, it will be able to generate multiple words by combining these tokens.
- SentencePiece – This approach was developed at Google and is used in models like T5 and GPT-3. This takes text as a stream of bytes. This allows to create tokens independent of language. It is very effective in languages which does not rely on word boundaries.
Uses of Subword Tokenization
There are various scenarios in which subword tokenization technique is used:
- Handling new words: To handle rare words, typos and generating new words (out-of-vocabulary words by combining subwords) which were not part of model training.
- Morphologically rich languages – To capture semantic similarities by recognizing common roots, prefixes, or suffixes across words.
- Machine Translation – Helps models generalize across different forms of words.
- Optimize Vocabulary Size – Using whole words increases the vocabulary size significantly, making models harder to train and less efficient.
Character Tokenization
Character tokenization is a NLP technique, where text is split into individual characters rather than words, phrases, sentences, sub-words or other units. Every single character – a letter, punctuation, or even space, all are considered as tokens. This approach is very useful when understanding every small unit of language is important. This is used in languages with complex morphology, in order to handle spelling checks & variations or with text that contains uncommon patterns such as hashtags, usernames or code.
Input: "TOKENIZATION"
Output: ["T", "O", "K", "E", "N", "I", "Z", "A", "T", "I", "O", "N"]
Input: "NLP"
Output: ["N", "L", "P"]Use Cases of Character Tokenization
- Text Generation Models – Character tokenization is used in generation of text character-by-character. This is used in advanced models like GPT and RNNs. This is particularly effective for creative tasks, such as generating new phrases, stories, poetry or fantasy text etc. This is more effective than the word-level text generation.
- Spelling and Grammar Correction – Character tokenization can also be used in spelling checks and grammer correction. This enable models to learn common misspellings or typing errors. While looking at the word character patterns, models can learn which character combinations are valid and which are not. This is very helpful in tasks related to grammar correction, spell-check and even sentence correction.
- Rare Words Handling and Morphology-Rich Languages – Character tokenization helps to manage and keeps the vocabulary size in limit, by reducing the number of unique tokens required. This is more useful while working with morphologically rich languages or those having a large number of unique words. Also, it makes it easier to handle rare words and out-of-vocabulary words by breaking them into its used characters.
- Name Entity Recognition and Parsing Non-Standard Text – Character tokenization is useful in texts with a lot of special characters, such as usernames, URLs, or chemical formulas. It also allows for finding named entities with unique spelling that is different from the standard word boundaries.
- Speech Recognition and Translation – Character tokenization is also used in speech recognition and translation of text from one language to another.
- Sentiment Analysis and Emotion Detection – In social conversations, emotions are represented by emoji’s, or stylish texts. These emotions and sentiments can be better understood using character tokenization rather than word tokenization. This can help improve the understanding of models with regard to sentiments and emotions represent in informal language.
Tokenization Algorithms
Algorithm – Rule-Based Tokenization
Rule-based tokenization applies specific rules to handle white-spaces, punctuation, contractions, hyphenated words or even regular expressions. Rule-based tokenization follows the straight-forward rules which are not suitable to understand complex language or informal text.
import re # Regular expression library
# Define text
text = "Tokenization in a major technique in NLP. Let's learn!"
# Define regex pattern for word tokenization
# r'\b\w+\b' - Regular expression - matches of any space or character between words
tokens = re.findall(r'\b\w+\b', text.lower()) # find all token and collect as list
print(tokens)
# Output: ['tokenization', 'in', 'a', 'major', 'technique', 'in', 'nlp', 'let', 's', 'learn']Algorithm – Tokenization with NLTK
Natural Language Toolkit (NLTK) provides different functions for word and sentence tokenization. This Python library is popular for NLP preprocessing.
import nltk # nltk Python library
from nltk.tokenize import word_tokenize, sent_tokenize
nltk.download('punkt_tab') # download punkt_tab library
# Given text
text = "Tokenization in a major technique in NLP. Let's learn!"
# Word tokenization
word_tokens = word_tokenize(text) # Use method word_tokenize to get word tokens
print("Word Tokens:", word_tokens)
# Output => Word Tokens: ['Tokenization', 'in', 'a', 'major', 'technique', 'in', 'NLP', '.', 'Let', "'s", 'learn', '!']
# Sentence tokenization
sentence_tokens = sent_tokenize(text) # Use method sent_tokenize to get sentence tokens
print("Sentence Tokens:", sentence_tokens)
# Output => Sentence Tokens: ['Tokenization in a major technique in NLP.', "Let's learn!"]Algorithm – Subword Tokenization Techniques
Some of the most frequently used techniques for subword tokenization are Byte-Pair Encoding (BPE), WordPiece, and SentencePiece.
Algorithm – Byte-Pair Encoding (BPE)
BPE begins by taking each character as a token and then iteratively merges pairs of adjacent characters with most frequently appearing sub-words.
# Byte-Pair Encoding using Hugging Face’s Tokenizers library
from tokenizers import Tokenizer, models, trainers, pre_tokenizers
tokenizer = Tokenizer(models.BPE()) # Initialize a BPE Tokenizer
trainer = trainers.BpeTrainer(vocab_size=1000, min_frequency=2) # create a trainer object
# Training data
training_text = ["Tokenization in a major technique in NLP. Let's learn it in detail!"]
# Train tokenizer
tokenizer.pre_tokenizer = pre_tokenizers.Whitespace()
tokenizer.train_from_iterator(training_text, trainer)
# Tokenize input text
output = tokenizer.encode("Tokenization in a major technique in NLP.")
print("Subword Tokens:", output.tokens)
# Output => Subword Tokens: ['T', 'o', 'k', 'e', 'ni', 'z', 'a', 't', 'i', 'o', 'n', 'in', 'a', 'm', 'a', 'j', 'o', 'r', 't', 'e', 'c', 'h', 'ni', 'q', 'u', 'e', 'in', 'N', 'L', 'P', '.']Algorithm – WordPiece
This approach is used by models like BERT. This approach also starts with a character based vocabulary and then perform iterative mergers on the subwords using a probabilistic model.
# WordPiece lagorithm using Hugging Face’s Tokenizer
from transformers import BertTokenizer
# Load pre-trained WordPiece tokenizer model
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# Tokenize input text
text = "Tokenization in a major technique in NLP."
tokens = tokenizer.tokenize(text) # Tokenize the given text using wordpiece algorithm
print("WordPiece Tokens:", tokens)
# Output => WordPiece Tokens: ['token', '##ization', 'in', 'a', 'major', 'technique', 'in', 'nl', '##p', '.']Algorithm – SentencePiece
This approach was developed at Google and is used in models like T5 and GPT-3. This takes text as a stream of bytes. This allows to create tokens independent of language.
- Step 1 – Create training data file with name ‘sentencepiece-training-data.txt’. Following text added to it:
# content of 'sentencepiece-training-data.txt' file
Tokenization in a major technique in NLP. Let's learn it in detail!- Step 2 – Use the following SentencePiece algorithm to tokenize the text.
# Using sentencepiece library
import sentencepiece as spm
# Train SentencePiece model
spm.SentencePieceTrainer.train(input='sentencepiece-training-data.txt', model_prefix='m', vocab_size=30)
# update vocab_size according to the training data
# Load trained model
sp = spm.SentencePieceProcessor(model_file='m.model')
# Tokenize text
tokens = sp.encode("Tokenization in a major technique in NLP.", out_type=str)
print("SentencePiece Tokens:", tokens)
# Output => SentencePiece Tokens: ['▁', 'T', 'o', 'k', 'e', 'n', 'i', 'z', 'a', 't', 'i', 'o', 'n', '▁i', 'n', '▁', 'a', '▁', 'm', 'a', 'j', 'o', 'r', '▁', 't', 'e', 'c', 'h', 'n', 'i', 'q', 'u', 'e', '▁i', 'n', '▁', 'N', 'L', 'P', '.']Tokenization in Transformer Models
Transformer is the advanced architecture used with NLP models. Advanced NLP models like BERT, GPT and T5 follows transformer architecture. Transformer based models requires tokenization according to their architecture. These models are using subword tokenization techniques like WordPiece and SentencePiece. This helps them to optimize the vocabulary size with the diversity of language.
Special Tokens in Transformers
For model specific requirements, these transformer tokenizers also include special tokens like:
[CLS]: This is the beginning of a sentence token in BERT. This is used for sentence-level tasks.[SEP]: Separator token to identify the difference in sentences.[PAD]: Padding token to maintain equal length inputs.
from transformers import BertTokenizer
# Initialize BERT tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# Sample text
text = "Tokenization in a major technique in NLP."
# Preprocessing and Tokenization
# Tokenize text with padding and truncation
encoded_input = tokenizer(text, padding=True, truncation=True, max_length=10, return_tensors="pt")
# Display tokenized output
print("Token IDs:", encoded_input['input_ids'])
print("Token Type IDs:", encoded_input['token_type_ids'])
print("Attention Mask:", encoded_input['attention_mask'])
# Output
# Token IDs: tensor([[ 101, 19204, 3989, 1999, 1037, 2350, 6028, 1999, 17953, 102]])
# Token Type IDs: tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
# Attention Mask: tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])Challenges in Tokenization
Tokenization presents unique challenges, particularly for languages with complicated grammar, informal text, or multilingual content. The most common challenges of tokenization include:
- Ambiguity: There are words in different languages, which can have multiple meanings or purposes in the sentence. Sometimes this depends on the context, in which that sentence was used. This causes ambiguity over the meaning of word and in result on the boundary of the token.
- Compound Words: Many languages, such as German and Finnish, have a convention of writing compound words. This makes it difficult to separate the meaningful token unit from the word.
- Contextual Sensitivity: Traditional tokenization methods like rule-based tokenization and word tokenization are not sufficient to handle abbreviations, slang or typos in informal language. These tokenization techniques are able to understand the context of the given text.
- Efficiency: The tokenizer must have efficiency to run on computation resources. This is important to handle large amount of data on which these tokenizer NLP models like BERT and GPT-3 can be trained.
Solution to Tokenization Issues
- Subword Tokenization: Subword tokenization helps solve problems related to out-of-vocabulary words and can handle complex language patterns.
- Dynamic Vocabularies: Adaptive tokenization methods like BPE and SentencePiece can better handle vocabulary and tokenization based on the text frequency.
Conclusion
Tokenization is the first level of any NLP task. Tokenization range from simple word processing to advanced transformer-based language modeling. There are various types and methods of tokenization, such as word, sentence, subword, and character tokenization. Each method is suitable for certain tasks and challenges in NLP. Advanced models like BERT and GPT have been using subword tokenization to handle issues related to vocabulary size, out-of-vocabulary (OOV) words, and language diversity. A robust tokenization pipeline is a keystone to process and structure data, that NLP models can read. This helps in improving performance and effectiveness of NLP applications.
Learning about tokenization is important to build a strong foundation to work with NLP models. This learning will also help to elaborate and work on more complex NLP applications.
LLM code snippets and programs related to Tokenization in NLP, can be accessed from GitHub Repository. This GitHub repository all contains programs related to other topics in LLM tutorial.
Related Topics
- Natural Language Processing (NLP) – Comprehensive GuideNatural Language Processing (NLP) is a technology in the artificial intelligence domain that involves interaction between human communication and machines understanding. It empowers machines to process human languages in a meaningful and useful way. It enables machines to learn & understand human languages and become capable to generate meaningful output. This makes it possible for…
- Recurrent Neural Networks (RNNs) – Language ModelsWhat are RNNs (Recurrent Neural Networks) Recurrent Neural Networks, or RNNs, are variants of artificial neural networks. They have been designed for processing sequential data. Other than the conventional feed-forward neural networks, the connections in RNNs loop backward to themselves, which allows it to create and maintain memory of past inputs. This property makes RNNs…
- What are N-Gram Models – Language ModelsN-Gram Models N-Gram models are a fundamental type of language model in Natural Language Processing (NLP). These models predict the probability of a sequence of words with regard to the previous word in a fixed window, referred to as “n.” These models have been used in simpler language-related tasks and provide the foundation for more…
- What are Large Language Models (LLMs)Large Language Models (LLMs) have become the new paradigm for interacting with technology in NLP-based applications. LLMs are taking the center stage in both understanding and generating human language, ranging from conversational chat-bots to graphics generation systems. This article covers what exactly LLMs are, focusing on their main attributes and importance in NLP. What are…
- What is Tokenization in NLP – Complete Tutorial (with Programs)What is Tokenization Tokenization is one of the major technique in Natural Language Processing (NLP) preprocessing that basically converts raw text into smaller, structured and organized units called tokens. These tokens can be words, subwords, sentences, or even characters. The size of tokens would depend on what form of processing is in view. Why Tokenization Matters in NLP Tokenization is important because Natural Language Processing (NLP) models cannot process texts without breaking it down into some form…